This is going to be a long post, collecting many years of work, some of which was done by my colleagues Kuldeep Meel and Raghav Kulkarni. They have both significantly contributed to this work and I owe a lot to both. The research paper is available here (accepted to SAT’2019) and the code is available here. Build instructions are at the bottom of the post. Part 2 will deal with exploring the data in more detail.
I always had a fascination with data when it comes to SAT solving. My SAT solver, CryptoMiniSat always had very detailed stats printed to the console. At one point, this fascination with data got to the point where tallying up data from the console (with AWK, like a true hacker) didn’t cut it, and I started dumping data to SQL.
An Early Attempt: Visualization
Out of the SQL data dumped, this website was born, back in 2012. This site displays pretty graphs like:
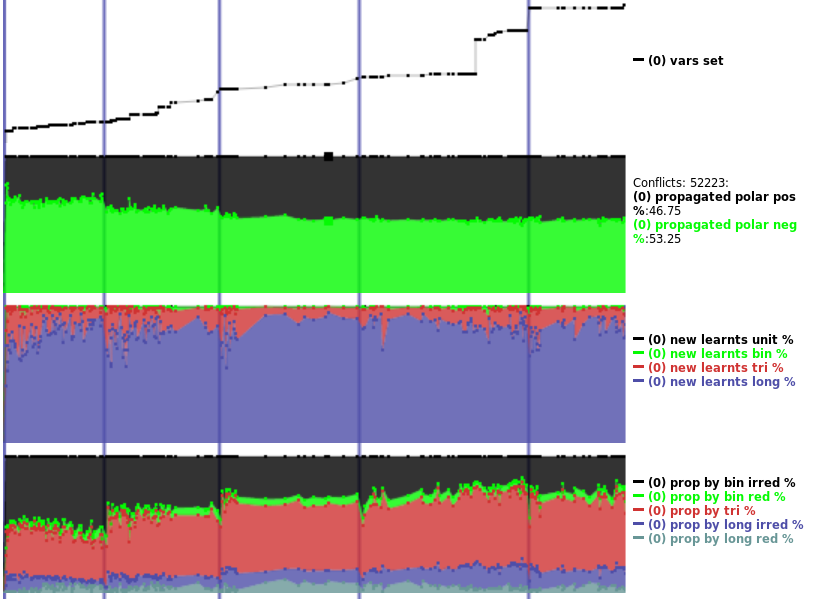
These graphs can show quite a bit of data, the above must be a few hundred data points. The data gathered is pumped to an SQL database, and then visualized. I felt like I am on to something. Finally, I was going to be able to explain things.
But I was able to explain very little. Some things were quite obvious, like how industrial and cryptographic instances’ variable polarity distributions were so different. Above, the black/green graph shows a cryptographic instance, and the distribution is 47% vs. 53%. On a typical industrial instance, the same graph looks like:

Here, the polarity distribution is 6% vs 94%. This is easy to see with the human eye. But I was gathering tons more data, many megabytes per instance. What was I going to do with all this data? How was I going to know what is good and bad behavior? And how would I make the solver work towards good?
SATZilla: Solver Selection Using Machine Learning
I wasn’t the only one trying to make sense of SAT-related data and improve solving based on it. SATZilla has done this before. There, the idea was to gather information — called features — about the input CNF problem, run multiple SAT solvers, save how much time it took for the solver to run, then create code that matches the CNF features to the preferred SAT solver. This creates a lines like:
num-vars num-clauses Best Solver 132 16730 Lingeling 375 46741 CryptoMiniSat 834 41690 CryptoMiniSat
Where the first N columns are the features and the last column is the label that we calculated to be correct. SATZilla uses many features, such as the number of horn clauses, the ratio of variables and clauses, etc. Once such a table has been built, with lines called labeled training examples, it uses a machine learning system, for example Decision Trees, to classify (i.e. guess) which SAT solver would be best for any CNF instance. So it generalizes, and can guess which SAT solver is best for a CNF it has never seen.
This system is interesting but has some drawbacks. First, for each data line one must run 5-10 SAT solvers on a CNF, potentially using up to 20-30’000 CPU seconds. Hence, each labeled training example is extremely expensive. If you know about the Big Data hype, you know that spending $2 on a single data point is not viable. Modern systems use millions of labeled training examples to learn a classifier. Secondly, this system was not designed to work in an industrial setting, where the CNF is not presented in a single file but piece-by-piece through a library interface.
Enter DRAT

DRAT is a system used to verify the resolution proof that modern SAT solvers generate. Basically, every unsatifiable problem that SAT solvers solve can be shown to be unsatisfiable through a set of operations called resolutions, that eventually lead to the equation 0=1, which is trivially false. A DRAT verifier can know exactly which clause was used by the SAT solver at exactly which time during the creation of the proof. Hence, DRAT knows a lot. It can actually tell, after the solving has finished, which parts of the SAT solving were absolutely useless, and which ones useful. A resolution proof with thousands of resolutions can be computed in seconds, which means cheap data.
When I first really understood DRAT, I realized, what if I could get all this data out of DRAT, and use it as a label for the millions of data points I already have? I have finally found a label, available at a huge scale, to train on.
The Beginnings of CrystalBall
What to train for was still a question that needed answering. Since DRAT is so intimately connected with learnt clauses, I decided to train for throwing away as many unneeded learnt clauses as possible. This would definitely make solving faster, by throwing away everything that is useless weight and making sure everything that is useful stays.
I must thank Marijn Heule who helped me with the first hack of DRAT-trim in early 2016 to get data out from from it. I hacked CryptoMiniSat to add Clause IDs to DRAT, so the verifier, DRAT-trim, could read and track these IDs. I now knew which clause was used in the proof and which wasn’t. This sounds really useful — you could now know which learnt clauses should have been thrown away the moment they were generated, since they were useless. Let’s see some data from modern CrystalBall (see at the bottom of the post how to download, compile and run):
sqlite> select count() from sum_cl_use where num_used>0; 51675 sqlite> select count() from sum_cl_use where num_used=0; 42832
The data says that about 50% of clauses were useful. Let’s see what is the average LBD value of the useful and useless clauses:
sqlite> select avg(glue) from sum_cl_use, clauseStats where sum_cl_use.clauseID = clauseStats.clauseID and num_used > 0; 6.71436865021771 sqlite> select avg(glue) from sum_cl_use, clauseStats where sum_cl_use.clauseID = clauseStats.clauseID and num_used = 0; 9.80162028389989
Nice. Let’s get the sizes, too, by replacing “glue” with “size”:
sqlite> select avg(size)... 12.2770198355104 sqlite> select avg(size)... 23.5734497571909
Cool. Size is a better discriminator? Let’s see another feature. Let’s get the average LBD of the redundant non-binary antecedents of the clause:
sqlite> select avg(antecedents_glue_long_reds_avg)... 4.88254061122689 sqlite> select avg(antecedents_glue_long_reds_avg)... 5.68082216847043
There are plenty more, well over a hundred, that is being measured, so I won’t bore you. I have a feeling you could write a few research papers just by running queries on this data.
I don’t know if you noticed, but something is odd here. SAT solvers only keep about 5-10% of all clauses. Just run a modern SAT solvers to completion and check how many clauses remain in the clause database. How is this compatible with 50% of clauses being useful? Well, we can use clauses for a while, then throw them away. But for that, we need much more than just whether a clause is useful or not. We need to know exactly when it was useful. Clauses can be used many-many times in a single proof.
We Need More Refined Labels
It turns out that having only whether a clause is being used is not good enough to compute useful labels. We need to know when, exactly, was the clause useful. So CryptoMiniSat and DRAT-trim was hacked to output into the DRAT proof exact conflict numbers when a clause was created. This, with some minor magic, would tell us exactly when each learnt clauses was used:
sqlite> select sum(num_used) from sum_cl_use, clauseStats where sum_cl_use.clauseID = clauseStats.clauseID and glue<=3; 332689 sqlite> select count() from clauseStats where glue<=3; 11221
For this problem, a clause that had LBD 3 or lower was used on average 332689/11221.0=29.65 times in the proof. Okay, how about clauses with LBD 4 or larger? It’s a trivial change in the above code, and gives us 5.95. Cool, the lower glue, the more it’s used in the proof.
Now that we know how to walk, let’s run. When was clauseID 59465 created and at what conflict points was it used in the proof?
sqlite> select conflicts from clauseStats where clauseID=59465; 101869 sqlite> select used_at from usedClauses where clauseID = 59465 order by used_at asc; 101870 123974 152375
This is an interesting clause. It was generated at conflict no. 101869, was used in the proof right after it was generated, at conflict no. 101870, and then it was used in the proof more than 20’000 conflicts later, twice.
The Data Pipeline
The idea is this: we are going examine every learnt clause at every 10’000 conflicts, and guess whether it’s going to be used in the future enough for it to be kept. If it’s going to be used enough in the future, we keep it. If not, we’ll throw it away. What do we need for this?
Well, we need a ton of labeled training examples. And for that, we need a truckload of data, one that generates so much that we have to throw away 96% and still end up with hundreds of MBs in under an hour. Also, we need this from a wide variety of problems, and we need to be able to debug the hell out of this data, because where there is tons of data, there are tons of NaNs, and negative clause sizes and the whatnot. So we need a data pipeline.
The first part of the pipeline we only run once, because it’s a bit expensive, about 3-10x slower than a normal CNF run, and looks like this:
- Run CryptoMiniSat without any clause cleaning, and write an SQLite database with all dynamic data gathered. The data written is about: the CNF (such as number of claues, etc.), the restarts (e.g. avg. LBD, restart length), the learnt clauses (e.g. LBD, size), and at every 10’000 conflicts the dynamic characteristics of the learnt clauses (e.g. activity, number of times used in a conflict the past 10’000 conflicts)
- Run DRAT, and dump all usage data to a file. Augment the SQLite data with the DRAT data
- Sample the data because otherwise it’s going to be too much. We need to sample smartly, though, because without biased sampling, the really weird cases will not be represented in the final data at all, and our machine learning system will not see some really interesting data. If we could store and process 1TB of data (you can generate that rather easily), we wouldn’t have this issue. But we can’t.
So now we have a ton of cool data that is very raw. This is going to be our baseline. We’ll keep this data in our stash and never modify it.
The second part of our data pipeline will use this stash of data to do all the cool things we want. This 2nd part is much-much cheaper to run (few seconds to a few minutes per CNF), so we will be able to run it as many times as we like, playing with all the cool parameters. This second part of the pipeline will:
- The data is stored normalized in SQLite for speed and space. For machine learning, we must denormalize it, to have everything related to decision on a single line.
- Create the labeled training data using Python Pandas for easy data manipulation and visualization
- Create a classifier using Python’s scikit-learn
- Spit out a C++ code we can compile into our solver
Getting Labeled Training Examples
In order to train a classifier, we need labeled training examples. These are lines like:
glue size used_last_10k_conflicts activity rank label 10 15 3 top half KEEP 7 10 1 bottom half THROW_AWAY 3 7 0 bottom half THROW_AWAY
Notice that this table has essentially two parts. The left part, i.e. everything apart from “keep”, called features, must be available to the solver during running. And the right part, “keep”, the label, which is computed using data from DRAT-trim. This latter the solver has no access to during running, this is our crystal ball, looking into the future. What we want is to predict the label given the features.
The left hand side, i.e. the features are not so difficult to do. Adding a new feature is now about 3-4 lines change in CryptoMiniSat and it’s essentially free in terms of speed. The data gathering only needs to run once (the 1st part of our data pipeline) and it is not running during solving. So, you can add as many features as you like. If they are useful, then you also need to add some lines to the solver so they will be available during running — of the 200+ only a few are really useful.
The right hand side, i.e. the labels are a completely different story, though. We know what is the future, kinda (yes, the future is a function of the past&present, but let’s not go there for the moment). So given the future, how do I label things? We need to use a heuristic. The good part is that we have a ton of information about the future, such as the distribution of all clause’s usage in the proof, and the number of times a particular clause is used in the future. But we still need to come up with something to decide KEEP/THROW_AWAY. A simple such heuristic is: if in the next 10’000 conflicts this clause will be used at least 6 times, keep it. Otherwise, into the bin it goes:
CASE WHEN
-- useful in the next round
used_later10k.used_later10k > 5
THEN "keep" ELSE "throw_away"
END AS `x.class`Nice! Remember that clauseID 59465 that I talked about above? Yeah, that would be labeled THROW_AWAY — it was only used 20’000 conflicts later. We have labeled our data, now we need to train a classifier, make it output C++ code and we are good to go. But before that, let’s play with Weka.
Data Analysis And Machine Learning with Weka
Weka is a cool tool for exploring data and building simple classifiers. You can get a free Weka course on Futurelearn, and I highly recommend it. The person who wrote it is the one who is giving the course and he is really cool. The denormalized, labeled data can be output to CSV (see at the bottom), which Weka can read:
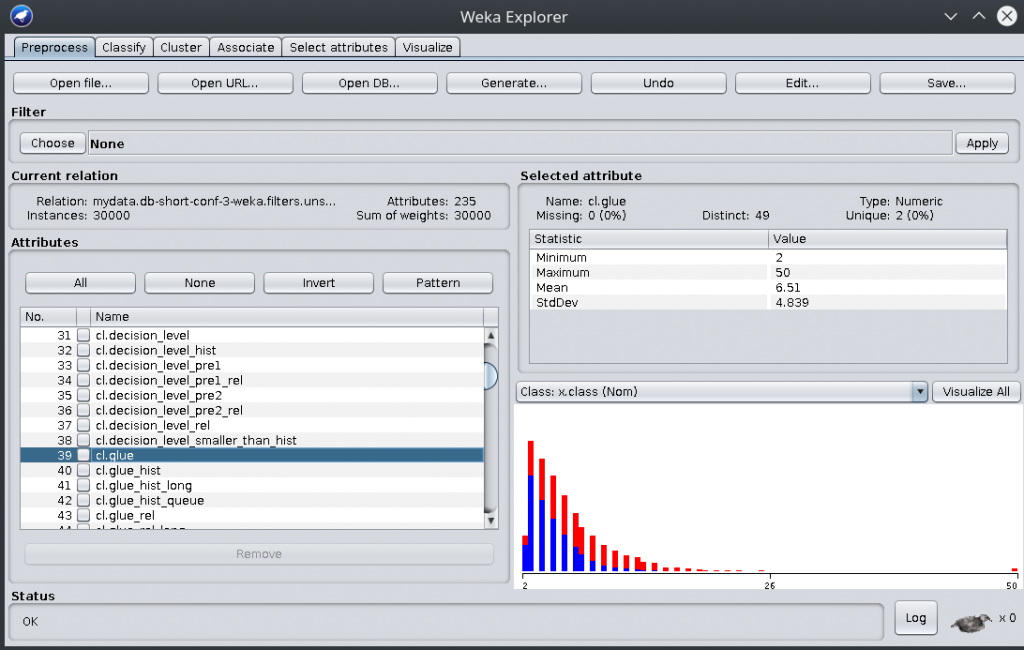
Here, you have Weka showing the denormalized set of features on the left, and showing the LBD distribution on the right. Blue color is for for lines labeled KEEP and red color is for lines labeled THROW_AWAY. As you can see, the distribution of blue vs red is not the same at all as the LBD value increases (hence LBD being a good discriminator, see glucose).
You can also visualize correlations:
You can also build classifiers based on this labeled data. Just don’t forget to delete the “sum_cl_use.*” features, as they are not really features, they are data from the proof verification. If you don’t delete them, Weka will cheat and use them in the classifier, which is like using the solution key during the exam :) Let’s create a classifier using Weka:
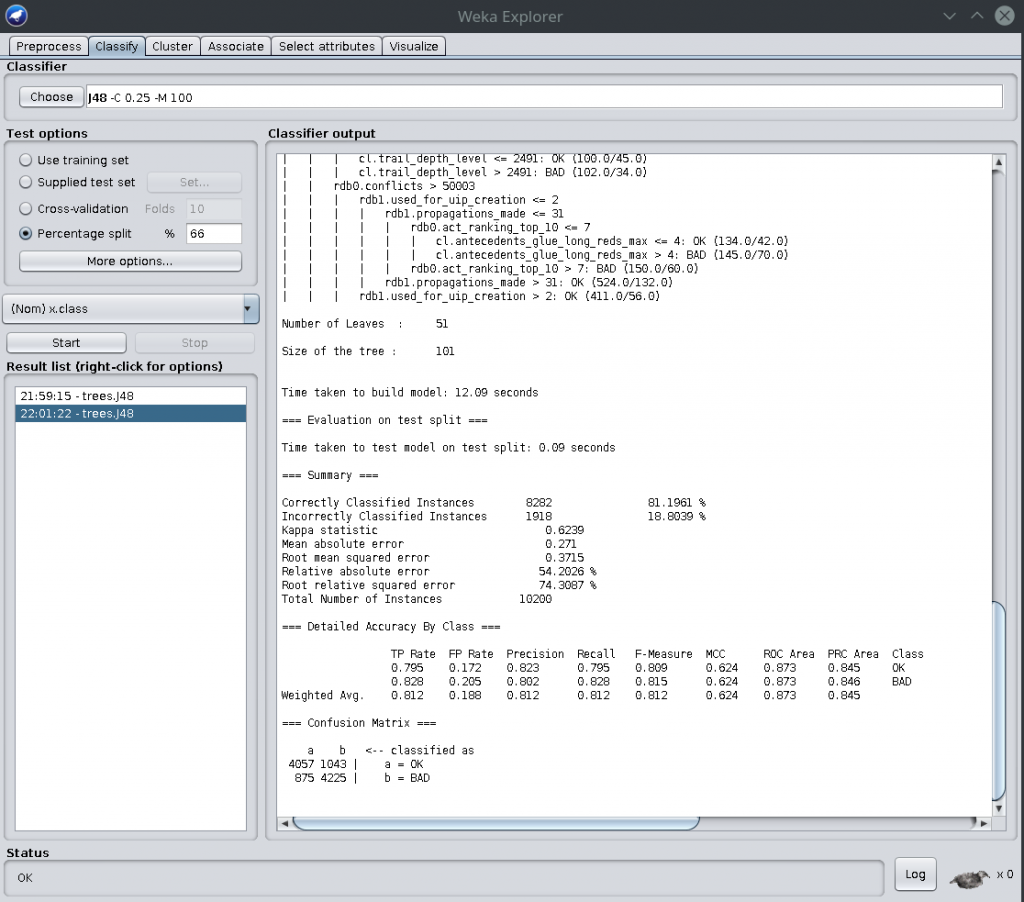
This shows a confusion matrix at the bottom. Nice. Total misclassification was 18% using the J48 decision tree algorithm with some minor tuning. Here is such an example decision tree (PDF here):
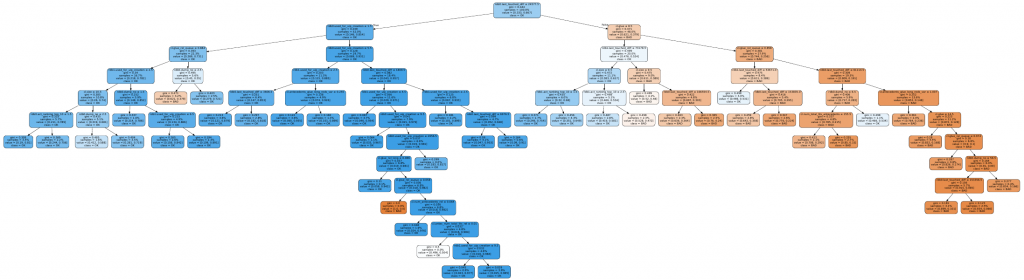
Weka is great in many ways, and I will forever be indebted to it. However, it’s just not gonna cut it for us. We need something a lot faster, and we need to be able to automate it and we need to be able to get C++ code out. Weka could do some of these, but I’m not a Java programmer, and Weka’s speed is nowhere near that of scikit-learn. However, if it’s your first time doing machine learning, Weka is an amazing tool.
Training a Classifier Using scikit-learn
Now that we have labeled training data, we need to create a classifier so that the solver, during running, can take the features it knows and guess the label KEEP or THROW_AWAY. There are many-many different classifiers that can be trained, and I have tried the most important ones, such as logistic regression, SVM, decision trees and random forests.
Let me pause here for a moment. If you haven’t done machine learning before, you might think — this is where the magic is. The classifier is where it’s at! And if you have done machine learning before, you know full well, it’s not here at all. It turns out that the quality and quantity of your data is way more important than the classifier you choose. It’s relatively easy to see why. If your data is messy, incorrect, or missing elements, no matter what classifier you use, no matter how amazing it is, it will give you bad results. Bad data, bad results. Every. Single. Time. Keep this in mind.
So, we have chosen our classifier, say, decision trees. Decision trees are easy to visualize, and you will need to debug the hell out of this, so it comes handy. After all, nobody wrote 1000 lines of python and it came out perfect the first time.
Now, there are still some things to deal with. First, we cannot possibly use all 200+ features in our prediction. We can generate the tables, but we need to be reasonable, and cut down the features to something much smaller, say, 20, during the running of the solver. To do that, we create a large random forest and then check which features were picked by the most trees. That gives us feature ranking (thanks to Raghav Kulkarni for this trick):
../predict.py "mydata-min.db-short-conf-0.dat" --name short [...] Feature ranking: 1 rdb0.used_for_uip_creation 0.1070 2 rdb0.last_touched_diff 0.0723 3 rdb0.act_ranking 0.0694 4 rdb0.activity_rel 0.0644 5 rdb0.sum_uip1_used 0.0641
So the top 5 features for this particular run are these. For different instances or different configurations, the top features may differ, and you probably want to sample X number of labeled training example from each problem, put it in a large data file and then run the feature ranking.
There are still some minor obstacles to overcome. Since about 95% of the clauses need to be thrown away, our labels will be very unbalanced. So we need to balance that. Also, how aggressive do we want to be with throwing clauses away? Should we err on the side of caution? Note that this is not about labeling anymore. The label has already been chosen. It’s about guessing the label. We are now tuning what’s called the confusion matrix:
X label label
KEEP THROW_AWAY
guessed 0.80 0.20
KEEP
guessed 0.05 0.95
THROW_AWAY
Here, we have 80% of things that we labeled as KEEP actually being guessed to be kept, while 20% of them are wrongly guessed as THROW_AWAY. So it’s kinda okay. We are better at guessing if something needs to be thrown away, though, there we only guess 5% of them wrongly. Maybe this a good balance, but if not, it can be changed as a weight parameter.
The system can also classify clauses into different types, using K-means clustering. Then it can train a different classifier for each clause type. The K-means clustering uses the already denormalized features, so it’s really trivial to do, though which features should be used for the clustering is a good question. I currently use the CNF features only (e.g. number of clauses, variables, ratio of vars/clauses, etc.), thereby clustering problems rather than clauses. One could could use any set of features though, it’s all automatic, including C++ code generation.
Actually, the C++ code generation. The system produces C++ code for decision trees, random forests and K-means clustering, ready for it to be compiled into the final executable. We have now created our clustering and classifier, and it’s all in C++ code. Let’s run it!
The Final Solver
This is the most fun part. And the cumulative effort of a lot of work. It’s really interesting to see all those thousands of lines of C++ and python churning out gigabytes of data, being boiled down to juts a few hundred lines of automatically generated if-then-else statements, running during solving. But there it is.
Let me talk about the good parts first. It’s very fast at evaluating whether to keep or throw away a clause. You don’t even notice it running. It doesn’t use much more memory than normal CryptoMiniSat (i.e. a few features were enough), and it correctly guesses the cluster where a clause belongs. It also guesses the labels correctly with very high probability. The final solver beats every solver from 2018 on the SAT competition 2014-17 instances.
Another great thing is that this system can be used to automatically train for specific problem types. This can be very significant in industry, where the instances are similar and training for a particular type of instance would make a lot of sense. Since this system tunes to the data it’s given, if it’s given data only about a particular type of instances, it will tune to them only, making the solver particularly good at them.
There is a bad part too, though: the built-in, rather sophisticated heuristic of keeping or throwing away clauses beats the system built. This makes me very sad, but some things make me hopeful. Firstly, the data is probably still messy. There are probably some bugs here and there, where some of the data gathered is not reliable. Secondly, the labeling is very-very rudimentary. If you have a look at that CASE statement above, it’s laughingly simple. Finally, the normal heuristic is quite smart, keeping some (simple) information about clauses, i.e. keeping some state over time, which the current machine learning system cannot do — the classifier has no memory.
Conclusions
This project, going back over 6 years, has been a tough one. All in all, it must have costed about 2 full years of work. A sane researcher would have abandoned it after about 2 weeks. In fact, we had a reviewer rejecting the paper, claiming that this work could be done in 2 weeks by her/his PhD student (I love such reviews). I sometimes wonder how much that PhD student charges for their time, because I might just pay it if they are that good.
Maybe we did the wrong thing, keeping going for so many years, but I think this could be a foundation of something much more interesting. It could be used not only to create machine learning models, but also to understand SAT solvers. With so much data at hand, we could finally understand some of the behavior of solvers, perhaps leading to some interesting ideas. And the data could be used for many other machine learning systems, too: guessing when to restart, guessing which variable to branch on, etc.
Build and Use Instructions
# Prerequisites on a modern Debian/Ubuntu installation sudo apt-get install build-essential cmake git sudo apt-get install zlib1g-dev libsqlite3-dev sudo apt-get install libboost-program-options-dev sudo apt-get install python3-pip sudo pip3 install sklearn pandas numpy lit matplotlib # Getting the code git clone https://github.com/msoos/cryptominisat cd cryptominisat git checkout crystalball git submodule update --init mkdir build && cd build ln -s ../scripts/crystal/* . ln -s ../scripts/build_scripts/* . # Let's get an unsatisfiable CNF wget https://www.msoos.org/largefiles/goldb-heqc-i10mul.cnf.gz gunzip goldb-heqc-i10mul.cnf.gz # Gather the data, denormalize, label, output CSV, # create the classifier, generate C++, # and build the final SAT solver ./ballofcrystal.sh --csv goldb-heqc-i10mul.cnf [...compilations and the full data pipeline...] # Let's use our newly built tool # we are using configuration number short:3 long:3 ./cryptominisat5 --predshort 3 --predlong 3 goldb-heqc-i10mul.cnf [ ... ] s UNSATISFIABLE # Let's look at the data cd goldb-heqc-i10mul.cnf-dir sqlite3 mydata.db sqlite> select count() from sum_cl_use; 94507