Uniform sampling is pretty simple: there are a set of solutions to a set of equations, and I want you to give me N solutions uniformly at random. Say, I have a set of equations that only has the solutions x=1…6, and I ask you to give me solutions uniformly at random. In this case, if the system is not cheating, it should give me solutions exactly like a random dice would give: 1..6, each with the same probability of 1/6. Now, if you give me nothing but 1’s I’d be slightly confused, and eventually would think you may be trying to cheat.
Uniformity is useful not only in gambling, but also e.g. if you want to make sure to cover a good chunk of the potential states in a system. Say, your equations describe how a program can run. Now, uniform solutions to these equations will be examples of the state space of your program. If you want to check that your system is in most cases doing the right thing, you can ask for uniform solutions at random and check the states for inconsistencies or unexpected behaviors.
Uniform Sampling of CNFs
One type of equations that is quite popular is to have all variables boolean (i.e. True/False), and equations being nothing but an “AND of ORs”, i.e. something like: “(a OR b) AND (b OR c OR d) AND (-f OR -g)”. These types of equations, also known as CNF, can express quite complicate things, e.g. (parts of) computer programs, logical circuits (e.g. parts of CPUs), and more. What’s nice about CNF is that there are many different tools to convert your problem language into CNF.
Given CNF as the intermediate language, all you need to do is run a uniform sampler on the CNF, and interpret the samples given your transformation. For example, you could translate your Ethereum cryptocurrency contract into QF_BV logic and blast that to CNF using e.g. the STP solver. Then you can get uniform random examples of the execution of your cryptocurrency contract using e.g. UniGen.
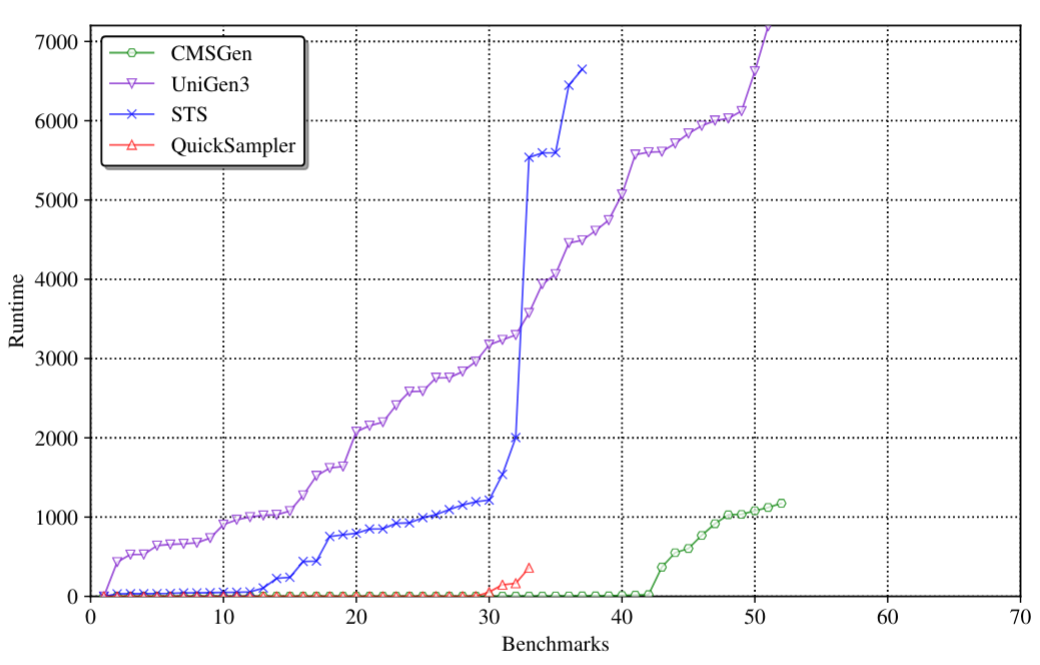
There are many different samplers for CNFs, and they mostly fall into two categories: ones that give guarantees and are hence truly uniform, and ones that don’t give guarantees and therefore fall into what we’ll call uniform-like samplers. These latter samplers tend to be significantly faster than truly uniform samplers, however, they can, and sometimes do, give non-uniform samples. I personally help maintain one truly uniform sampler, UniGen (PDF), and one uniform-like sampler, CMSGen (PDF). Other popular truly uniform samplers include KUS (PDF) and SPUR (PDF).
Catching Uniform-Like Samplers: Barbarik
If I give you a sampler and ask you to tell me if it’s truly uniform or simply uniform-like, what should you do? How should we distinguish one from the other, without looking into the internals of the system? It turns out that this is not a simple question to answer. It is very reasonable to assume that there are e.g. 2^200 solutions, so e.g. trying to prove that a sampler is uniform by saying that it should only output the same sample twice rarely is not really meaningful. In this latter case, you’d need to get approx 2^100 samples from a truly uniform sampler before it will likely give two colliding samples. While a uniform-like sampler may collide at e.g. only 2^60 (i.e. a trillion times earlier), that’s still a lot of computation, and only a single data point.
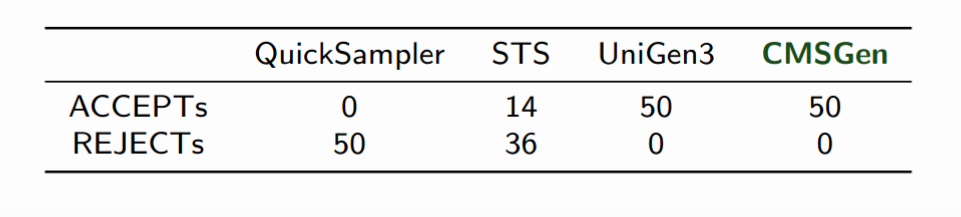
Doing this efficiently is the question that was on the minds of the authors of Barbarik. Basically, their idea was the following: take a CNF, remove all solutions but two, and blow up these two solutions into equally many solutions each. Say, you find two solutions to a CNF, one BLUE and one RED. Barbarik will take BLUE, make 100 blue balls out of it, and take RED, and make 100 red balls out of it. Then, it will give the CNF with the 200 solutions, half blue, half red, to the sampler under test. Then it asks the sampler to give it a bunch of balls. We of course expect approx 50%-50% red-blue distribution of balls from a truly uniform sampler.
Barbarik fails a solver if it is gives a distribution too far away from the 50%-50% we’d expect. Barbarik runs this check many times, with different example blue/red solutions that are “blown up” to multiple solutions. Given different base CNFs, and many tries, it is possible to differentiate the good from the bad… most of the time:
The Birth of CMSGen
When Barbarik was being created, I was fortunate enough to be present, and so I decided to tweak my SAT solver, CryptoMiniSat purely using command-line parameters, until Barbarik could not distinguish it from a truly uniform sampler. This, in my view, showcased how extremely important a test system was: I actually had a bug in CryptoMiniSat’s randomization that Barbarik clearly showed and I had to fix to get higher quality samples. We called the resulting uniform-like sampler CMSGen, and it was used in the function synthesis tool Manthan (PDF), that blew all other function synthesis system out of the water, thanks to its innovative design and access to high quality, fast samples from CMSGen:
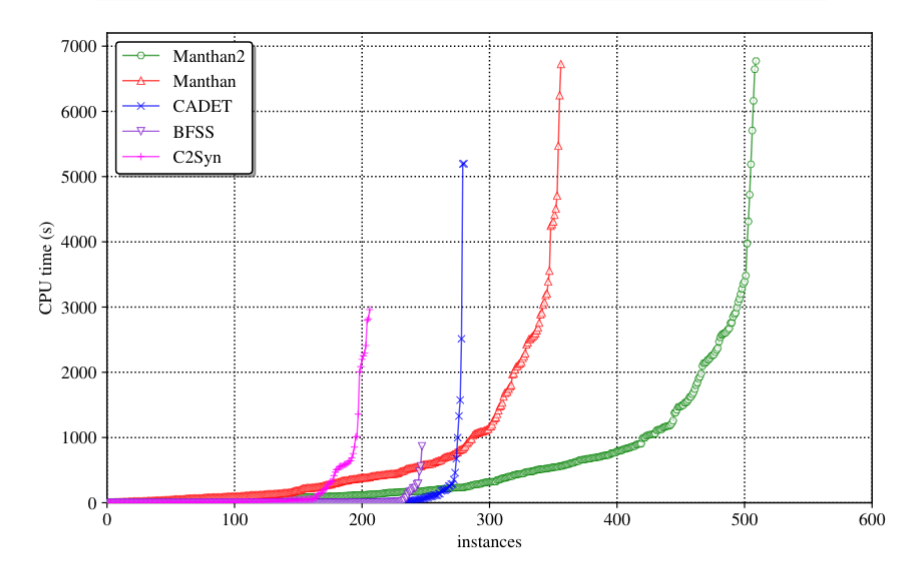
Notice that within 200 seconds Manthan outperformed all other function synthesis systems, even if we give the other system 7000 seconds to work with. If you are interested in the details of this crazy improvement over previous state-of-the-art, check out the slides here or the video here (these are all work of my coworkers, I am not an author).
While CMSGen was clearly fast and powerful, it bothered me endlessly that Barbarik couldn’t demonstrate that it wasn’t a truly uniform sampler. This eventually lead to the development of ScalBarbarik.
The Birth of ScalBarbarik
Since CMSGen passed all the tests of Barbarik, we had to come up with a new trick to distinguish it from truly uniform samplers. ScalBarbarik‘s (PDF) underlying system is still the same as Barbarik: we take a CNF, take 2 samples from it, and blow both of these samples up to a certain number. However, how we blow them up is where the trick lies. Before, they were both blown up the same way into solutions that are equally easy/hard to find. However, this time around, we’ll make one of the solution types much harder to find than the other. For this, we’ll use Vegard Nossum’s SHA-1 CNF generator (PDF) to force the system to reverse a partial, reduced-round SHA-1 hash, with some fixed inputs & outputs. This allows us to both change the complexity of the problem and the number of solutions to it rather easily.
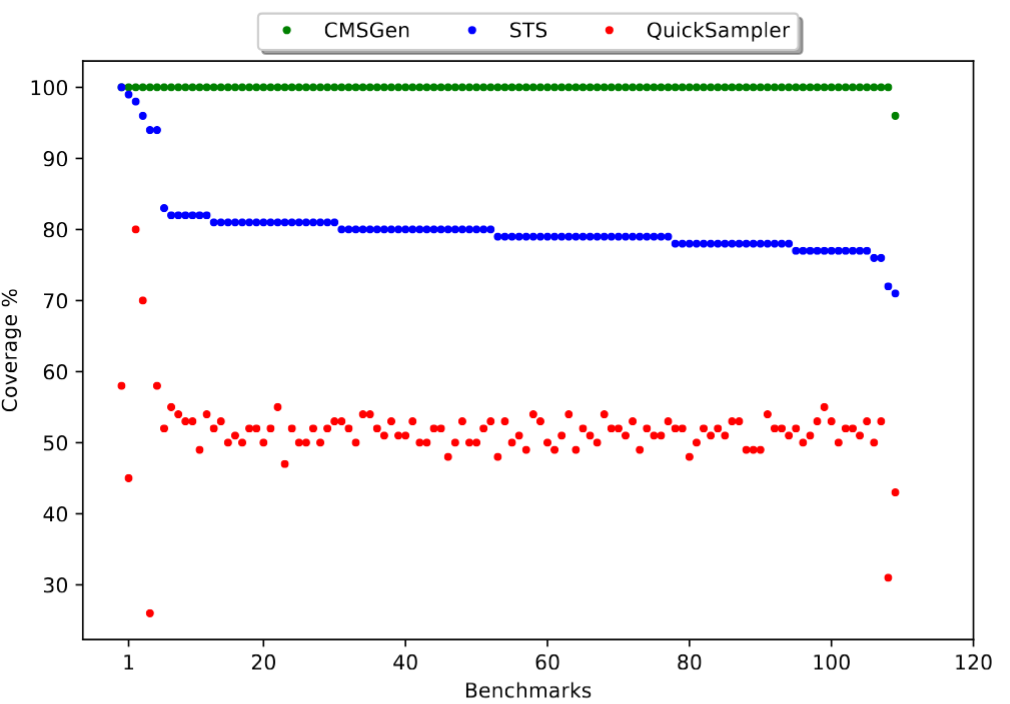
While one set of solutions will be hard to find, the other ones will be trivial to find — if one special variable is set to TRUE, the finding a set of solutions is trivial But when it’s set to FALSE, the system has to reverse a reduce-round SHA-1. The logic behind this is that the uniform-like systems will likely be finding the easy solutions with much higher probability than the hard solutions, so they will sample much more unevenly. Indeed that’s the case:
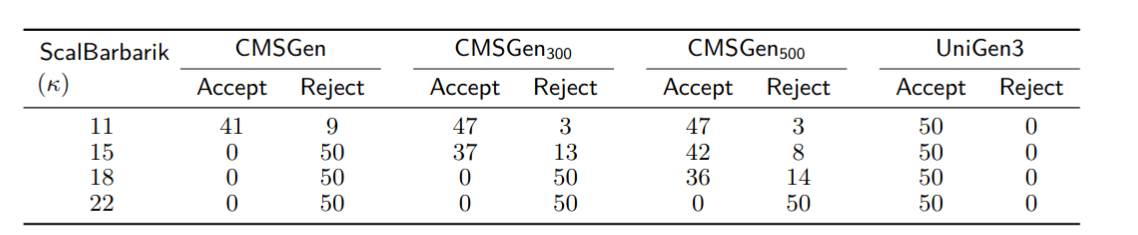
Note that as the hardness parameter is increased, CMSGen is rejected more and more often, and eventually it’s rejected for all CNFs. Also interesting to note is that QuickSampler and STS get both rejected, as before, but this time around, STS gets rejected for all 50 CNFs, rather than for only 36 out of 50. In other words, ScalBarbarik is overall a stronger/better distinguisher.
Conclusions
With the birth of Barbarik, a set of uniform-like testers were shown to be less than ideal, and a new, more robust near-uniform sampler was born, CMSGen. But as a the gauntlet has been throw down by CMSGen, a new tool emerged, ScalBarbarik, to help find the non-truly uniform samplers. With this cycle in mind, I hope that new, more elaborate, and higher-quality uniform-like samplers will emerge that will be able to beat ScalBarbarik at its own game, improving the quality of the sampling while maintaining the speed advantage that uniform-like samplers enjoy over truly uniform samplers. With better uniform-like sampling tools, hopefully we’ll be able to make headway in automated test case generation (imagine having it as part of all development IDEs), higher performance function synthesis, and hopefully even more diverse areas of interest for the general public.