Ganak (github), our propositional model counter, has won every single model counting competition track for the past two years. Perhaps it’s time to explain how that came about, and what are the ingredients of such a tool. Firstly, a propositional model counter is a tool that counts how many solutions there are to a set of boolean constraints of the form:
a V b
b V -cThis set of constraints has the following possible solutions:
abc
---
000
001
010
011
100
101
110
111But the ones highlighted in bold are not solutions, because the constraints make them incorrect. So we are left with 8-3=5 solutions. There is one more twist. Sometimes, we are only interested in the solutions over a set of variables, which we will call the sampling set, say “a” and “b”. Then we are only left with the solutions “01x”, “10x”, and “11x”, a total of 3 solutions, where “x” means we don’t care about the value , since it’s not in the sampling set.
The History of the Preprocessor: Arjun
Arjun (github) came about because we saw the B+E tool doing minimisation of the sampling set. Minimising the sampling set is important, because if the sampling set is e.g. only of size 10, then there are at most 2^10 things to count, but if it’s 20, then there are 2^20. It’s possible to minimise the sampling set sometimes: for example when we can prove that e.g. a=b, there is no need to have both “a” and “b” in the sampling set. Tricks like this can significantly lower the complexity of counting solutions. We enhanced B+E, and published this as a paper here.
In the end, it turned out that minimising the sampling set was really only the beginning: we also needed to make the input smaller. The fewer the constraints, and the fewer the number of variables, the easier it is to deal with the formula. This was not new to anyone, but it turns out that this minimisation was hard. Others have tried, too, but my advantage was that I came from the SAT world, with the CryptoMiniSat SAT solver under my belt, so I wrote an entire API (blogpost) for my SAT solver to be used as an input minimiser. This allowed me to try out many heuristics and write code easily, taking advantage of all the datastructures already inside CryptoMiniSat for constraint handling.
The History of the Counter: Ganak
The actual counter, Ganak (github), was something of another story. It started with a hack that my long-time collaborator Kuldeep Meel and I did in 2018, for a long evening and night in Singapore. This lead to the original Ganak paper which essentially added hashing to the system, thereby making it probabilistic, but also use a lot less memory, and thereby faster. I personally haven’t touched that project much, and instead focussed all my energies on the preprocessor, Arjun. I was pretty convinced that if I could make the preprocessor good enough, no matter what Ganak looked like, it would be good enough.
This strategy of focussing on Arjun mostly paid out, we did well in model counting competitions. The counter d4 was the main competitor at the time. Then SharpSAT-TD (paper) by Korhonen and Jarvisalo and came and it blew everything out of the water. That made me look at the Ganak source code first time in about 5 years, and I was appalled. We were putting a donkey, Ganak, on the rocket, Arjun, that I built, and we were doing OK, but looking at SharpSAT-TD, we were clearly racing a donkey against a cheetah. So In the spring of 2023 I sat down one morning and started replacing things I hated about Ganak, which was mostly everything.
Thus, the Ganak we know today was born. This gradual rewriting took about 2-3 years, continued during the summer and then the next spring. The most significant parts of this rewrite were that we cleaned up the code, added extensive fuzzing and debugging capabilities to it, added/adapted a lot of well-known SAT tricks for counting, integrated the tree decomposition (“TD”) system and parts of the preprocessor from SharpSAT-TD, and came up with a way to not only minimise the sampling set, but also the extend it, which can help in certain cases.
Ideas in Ganak and Arjun
We wrote a paper about Ganak (paper here) but to be honest, it only covers a very small ground of what we did. The change to Ganak between the original paper in 2019 to today is about 30’000 lines of code. Obviously, that cannot be explained in detail in just a few pages. Furthermore, the way academic publishing works, it’s not possible to simply list a bunch of ideas that were implemented — you need to explain everything in detail, which cannot be done with 30’000 lines of code. So, below is a bit of an “idea dump” that I have implemented in Ganak, but never published.
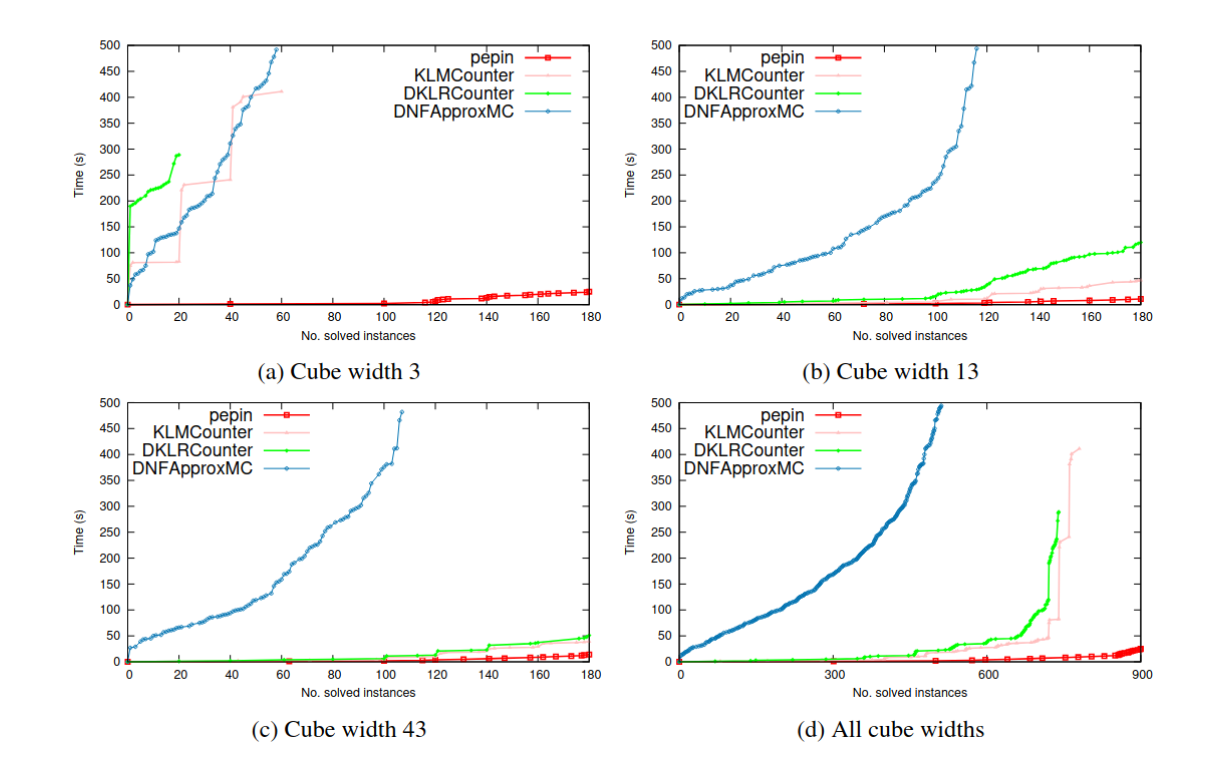
I might attempt at publishing some of them some day. Currently, I see little reward for doing so besides citations, and citations are not a great indicator in my view: lcamtuf is one of the best IT security professionals, ever, and has basically no citations. Besides, due to the “publish or perish” system in academia, there is a sea of research papers that most work gets lost in. I believe what matters most is performance and usability. Ganak does pretty well in this regard. It compiles to many platforms: Linux, Mac, both ARM and x86, and even emscripten in your browser. It supports more weight systems than other counters: integers, floats, exact rationals, complex numbers, primes, and multivariate polynomials over the rationals and floats. Ganak also uses less memory than other competing counters, while running faster. Besides, it’s regularly fuzzed and leaks no memory, so its output is rather trustworthy.
Without further ado, here are some ideas never published in Ganak, but which help the system run faster:
- Using and improving the Oracle SAT Solver Korhonen and Jarvisalo (PDF by the authors). Oracle is a specialised SAT solver that allows one to query with many so-called “assumptions” in the SAT query, i.e. checking if something is satisfiable under conditions such as “a=true, b=false” — but many-many of them. This kind of query is very slow if you use a normal SAT solver, but with Oracle, it’s super-fast. This allows us to remove unneeded constraints, and make the constraints smaller. I improved this tool in a few ways, mostly by integrating a local search solver into it, that can drastically speed it up, by finding a satisfying solution much faster. I have also improved its heuristics, e.g. by using a better LBD heuristic (PDF by authors). I have also improved its solution cache, by employing cache performance tracking, pre-filtering, and cache size limitation. Besides, I added a step-tracking to it so it can be deterministically limited in time.
- Improved version of tree decomposition originally by Korhonen and Jarvisalo (PDF here). This system computes the tree decomposition of a CNF via Flow-Cutter by Ben Strasser (PDF, code), however, the original system had a few issues. Firstly, it did a clock-limited run of the executable, which was unacceptable to me, as it makes the system non-deterministic: depending on the CPU it will run faster/slower thereby computing different values (it’s a local search algorithm, with many restarts). Also, running separate executables is very fragile. Secondly, and more importantly, it computed the tree decomposition of a CNF and then tried to find its centroid. But… what if the CNF was disjoint? What’s the single centroid of a forest? Slight issue. I fixed this by computing the top-level disjoint components and counting them separately. Although disjoint components sound really like an input issue, and not a counter issue, the problem is that our preprocessing is so strong that it can make a non-disjoint input into a disjoint input, thereby confusing the TD/centroid finding. Ooops.
- Special-casing some inputs. Because we detect disjoint top-level components, sometimes we end up with CNFs that are very weird, for example, with a sampling set size of 2. These CNFs can only have at most 4 solutions, so counting them via the incredibly complicated d-DNNF system is an overkill, likely to waste a lot of time via the start-up and tear-down. Hence, these CNFs are counted one-by-one via the trivial use of a standard SAT solver.
- Using CCNR by Shaowei Cai (PDF by authors) for speeding up the Oracle query. It’s a cool local search system, and it works really well. I wish I had fixed up its code because it’s a bit clunky and my colleagues gave me a hard time for it. Not research colleagues, of course. In research, quality of code is irrelevant — remember, only the number of citations matters.
- Adapting Vivification by Li et al. (PDF paper) to the model counting setting. The original system stops the SAT solver once when the solver restarts, rewrites all the clauses to be shorter when possible, and continues happily every after. This happily ever after is impossible in a model counting setting, because we never restart. Slight issue. What I wrote was basically a nightmare-fuelled 2-week, probably about ~2000 line craziness that rewrites the propagation tree and/or avoids the clause improvement, so that all the invariants of the propagation remain intact while the clauses get shorter. This is kind of like changing the wheels on a car while it’s running. I don’t recommend doing this without extremely thorough fuzzing and debug tooling in place, or you’ll run into a lot of trouble. (By the way, this system not only contracts clauses, but also performs subsumption — if I have built the system, I might as well use it all the way)
- Using an virtual interface for the Field we are counting over. With this system, the Field we are counting over becomes irrelevant for the counter. Instead, the counter can focus on counting, and the implementation of the interface can focus on the Field-specific operations. This has allowed me to add many-many Fields with very little overhead. The Field parses, prints, and handles the 0, and 1 points, and the + and * operators. This separation of concerns is I think the right way to go. Also, it allows someone to implement their own Field and use it without having to recompile anything.
- Zero-suppressed Field counting. When counting over a field, there are two special elements one needs to take care of: zero and one. Of this, the zero is quite special, because a+0=a, and a*0=0. So, in Ganak, we don’t initialise the zero field element. Instead, we keep it as a null pointer. When manipulating this pointer, like adding or multiplying, we can simply replace it with a copy of what we add to it, or, when multiplying, keep it a null pointer. This saves space and also reduces the number of pointer dereferences we need to perform.
- Extensive fuzzing infrastructure by Latour et al (code), with ideas taken from Niemetz at al (PDF here). Ganak and Arjun both have many options that allow the fuzzer to turn off certain parts of the system, or push them to the extreme, thereby exercising parts of them that would otherwise be impossible to reach. The paper I linked to explains how adding the options to the fuzzer, and setting them to all sorts of values, can help the fuzzer reach very hard-to-reach parts of the code, thereby exposing bugs in them easier.
- Extensive debug infrastructure. Finding issues via fuzzing is only part of the deal, one must also be able to debug them. For this, Ganak has a 4-level debug system where progressively slower self-checking can be turned on so as to find the first place where the bug manifests itself as precisely as possible. The last level of debug checks every single node in the d-DNNF that Ganak builds, and exits out on the first node that the count is incorrect. The debug infrastructure also comes with a verbosity option that prints out full, human readable, structured, coloured logs for each major decision point in the d-DNNF. Overall, just the debug code of Ganak is likely 2-3 thousand lines of code. This may sound excessive, but Ganak can self-check its state at every node, and ensure that there is at least a path forward to counting the correct count, at almost all nodes. Apparently some have attempted to do what we did in our paper on Ganak, but bumped into issues they couldn’t resolve. I can confirm that without the appropriate fuzz and debug infrastructure, it would have been impossible for us to figure the things out we published in that paper.
- Cache-optimised, lazy component finding. When a decision and propagation happens in the CNF, we must check whether the system has fallen into disjoint components. If so, we can count the components separately, and then multiply their counts — a property of a Field. This greatly helps in doing a lot less work. However, this means we must examine every single variable in the system, and see if it’s connected to the others through clauses at every node — often millions, or even 100s of millions of times during counting. Normally, d-DNNF counters do this by going through all the so-called occurrence list of all variables, recursively, and see if they encounter all variables. The issue with this is that it is extremely expensive, up to 50% of the total runtime, and furthermore, it re-examines parts of the clauses that were not touched by the newly set variables. However, it’s not easy to fix this: doing something very smart to a system that is very fast but dumb can slow down the system, since the smart thing can often take more time to compute than doing the dumb thing fast. So I pulled an old trick out of a hat, one that I learned from a paper by Heule et al.: time stamping. Basically, you keep a time stamp for each data element you touched, and as long as you can decide cheaply that you don’t need to recompute something based on the timestamp, you are good. We keep stamping each variable when its value is changed, and then we know what parts of the clauses need to be re-examined, based on the stamp on the clause and the stamp on the variable. I implemented this in a cache-optimized way, similarly how SharpSAT does it, laying it all out flat in the memory, putting clauses next to each other that will be dereferenced after one another — a trick I learned form MiniSat.
- Prefetching of watchlists, and using blocked literals. Prefetching of watchlists is one of the very few things in SAT solving that was my idea. Basically, whenever a literal is set, its watchlist will be examined shortly. Hence, we can prefetch the watchslit the moment the literal is assigned, so as to prevent the CPU from stalling when the literal’s watchlist is invariably examined. This prefetching can be extended to the component finding, except there it’s occurrence lists and not watchlists. Secondly, I added blocked literals, another cache-optimising trick, by Chu et al (paper). Blocked literals are widely used by modern SAT solvers. SharpSAT missed it because it was written before this trick was known, so I added it in.
- Recursive Conflict Clause Minimisation by Sörensson and Biere (paper). This was a trivial lift-and-shift from the MiniSat source code. There’s nothing much to say here other than it’s pretty well-known thing, but was not known at the time of SharpSAT. I believe there is nowadays a much better system by Fleury and Biere that does efficient all-UIP minimisation (paper). If you wanna lift-and-shit that code into Ganak and win the model counting competition, be my guest — all Ganak is always open source and online at all points in time, I have no energy to hide code.
- Tight monitoring and management of memory usage. One of the first things you will notice with some model counters is that they eat all the RAM you have and then get killed by the kernel for lack of memory. This is unfortunately encouraged by the model counting competition guidelines which give massive amounts of memory, up to 64GB, to use by the counters. However, when you are testing your counter, almost all cluster systems have approx 4GB of memory per core (or less) in their nodes. The cluster I use has 160 cores per node and each node has 768GB of RAM, giving 4.8GB/core. Hence, if I want to test my counter without wasting resources, it should use at most 4.8GB of memory. Since I wanted to win the model counting competition, and for that I needed to test my system a lot, I optimised the system to use about 4.5GB memory at most. This is approx 10x less than what many other counters use. The way I did this is by (1) making sure no memory is leaked, ever, (2) precisely accounting for all memory usage and (3) deleting cache items that are occupying too much memory, ruthlessly. This required a using the valgrind memory leak detector, and a lot of use of valgrind’s massif heap profiler for many different types of inputs. This ensured that Ganak uses only the required amount of memory, and can safely and efficiently run in memory-constrained environments. In fact, Ganak would have won all tracks in both previous model counting competitions with only 1/10th of the allowed memory use (i.e. 6.4GB instead of 64GB).
- A few more things that I can barely remember. For example, watchlists or clauses(?) were reverse-visited. Binary clauses were in the same watchlists as the normal clauses, but they can use a specialised watchlist and be visited faster. Clauses were removed from the watchlist using the “switch-to-the-end” trick which has been shown to be less efficient than simply overwriting. The original Ganak allocated memory for the component, hashed it, then deallocated the memory, but it could have called the hash in-situ, without the allocation, copy, and de-allocation. The original Ganak also used a hash function that was optimised to hash very large inputs, which made it impossible to compile to emscripten due to the CPU intrinsics used, and besides, it was unnecessary because it only had to hash a few KB at most. So I switched to chibihash64 by nrk.
The above took about 3-4 years of work, on-and-off, since I don’t normally get paid to do research. The total time I worked on Ganak being paid to do it was about 4-5 months. So it was mostly just passion and having some fun. The code at least is not absolutely unreadable, and there are a lot of seatbelts around, about 5-10% of the code is asserts, and there are entire sets of functions written solely to do self-checking, debug reporting, etc.
I will likely not publish any of the above ideas/improvements. Some are, I think, publishable, for example the the vivification, but especially that code is nightmare-inducing to me. The fuzzing and debugging while important to me, as I am interested in tools that work, is hard to publish and not too novel. Memory management again falls into this weird place where it’s not very novel but necessary for usable tools. Supporting many fields is just a basic requirement for a well-functioning system, besides, it’s super-easy to do, if set up right. The rest is just basic copy-paste with minor adjustment. I think the use of CCNR is actually quite fun, but I hardly think it’s worth a paper. It’s shaving 30-40% time off of a very slow-running (but necessary) part of the preprocessor, and I was very happy when I discovered it.
I hope you appreciated this somewhat long list. The code can of course be examined for all of them, and you can lift-and-shift some/all the ideas into other tools and other systems. I left quite a lot of comments, and if you turn on VERBOSE_DEBUG and set verbosity very high (say, “–verb 100”) you should be able to see how all of them work in tandem.