Having won the SAT Race with CryptoMiniSat, I think I can now confess that I still don’t understand conflict generation. So today, I sat down and I tried to understand it. The result is some fun code, a lot of reading, and great pictures. Let me share with you these auto-generated graphs — the generator will be released with CMSat 3.0.0, so you will be able to generate them, too. These graphs show something called an ‘implication graph’, which is nothing more than a graphical way to show how propagations were made by the reasoning engine. For instance, if variable x1 and x2 are both FALSE, then clause ‘x1 V x2 V x3’ will force x3 to be TRUE to satisfy the clause. Okay, so much for talk, let’s see the graphs!

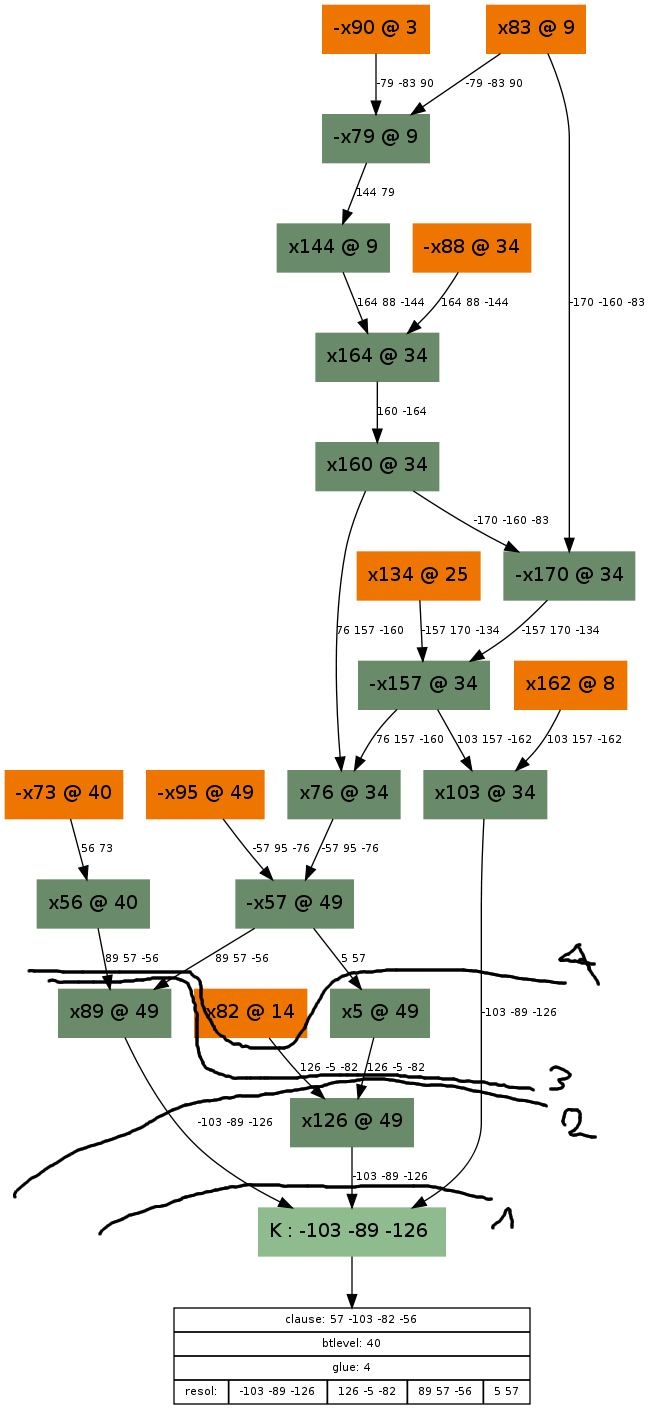
Our first implication graph had a clause “-70 55 42” (light green box) that caused a conflict — that is to say, somehow the variable setting {x70=TRUE, x55=FALSE, x42=FALSE} was set, the SAT solver realised that this is wrong, and something has to be done. Let’s look at what lead here! Guesses are coloured orange here, so it seems we made the following guesses during our SAT solving: x71=TRUE, x73 = FALSE, x42=FALSE. Now, we could just say, oh, well, setting x73 to FALSE was a dumb idea, just reverse that guess, and be done with it. That’s the easy (and the fast) way, but we are less lazy than that and we want to understand the reasons. So we do something called the conflict analysis to find something called an asserting clause that will not only let us reverse the guess x73=FALSE, but will also give the SAT solver a reason why that is a necessary assignment given its previous guesses and their consequences.
Consequences in the graph are coloured dark green, and there are exactly 3 of them: x70=TRUE, x55=FALSE and x56=TRUE. Each of these is a consequence of a clause that is in the SAT solver, marked on the edge(s) leading to it. For example, x56 is set to TRUE, because of the guess x73=FALSE and the clause “x56 V x73” marked on the edge leading to x56. A consequence that has one edge leading to it was propagated by a 2-long clause, a consequence that has 2 edges leading to it was propagated by a 3-long clause (e.g. consequence “x70=TRUE”, propagated by “x70 V x55 V x73”), etc. Okay, so how do we get to the reason? Well, we start out with the conflict, the clause “-x70 V x55 V x42” (at the bottom), and we do resolutions with this clause, going bottom up. We do as many resolutions as needed to reach the first UIP (also called “articulation vertex” or “dominator”), which is a unique point on the graph through which all paths go through from the highest decision level guess, in this case x73=FALSE, at decision level 56 (noted with a @56). If you take a look, the paths from x73=FALSE diverge from the very first point onwards, and there is no single point where they converge again. This means that the (first and only) dominator will be x73=FALSE itself, and we have to resolve with all clauses on the path:
- Start with clause “-x70 V x55 V x42”
- Resolve with clause “x70 V x55 V x73”
- Resolve with clause “-x55 V-x56 V -x71”
- Resolve with clause “x56 V x73”
This list is noted on the bottommost box’s lowest entry. When we resolve with these clauses, we are actually doing cuts on the graph, like this:

My drawing capabilities aren’t exactly great, but you can see that the cuts are successively higher and higher, until we reach the cut that has on its outer part the literals -x73, x71 and -x42. Unsurprisingly, exactly the inverse of these literals are what make up the final conflict clause. Now, if we unroll the implications until decision level 47 (but not the guess x42=FALSE), then with this clause added, variable x73 will propagate to TRUE automatically, essentially reversing the wrong guess — but also giving a reason why it needs to be reversed.
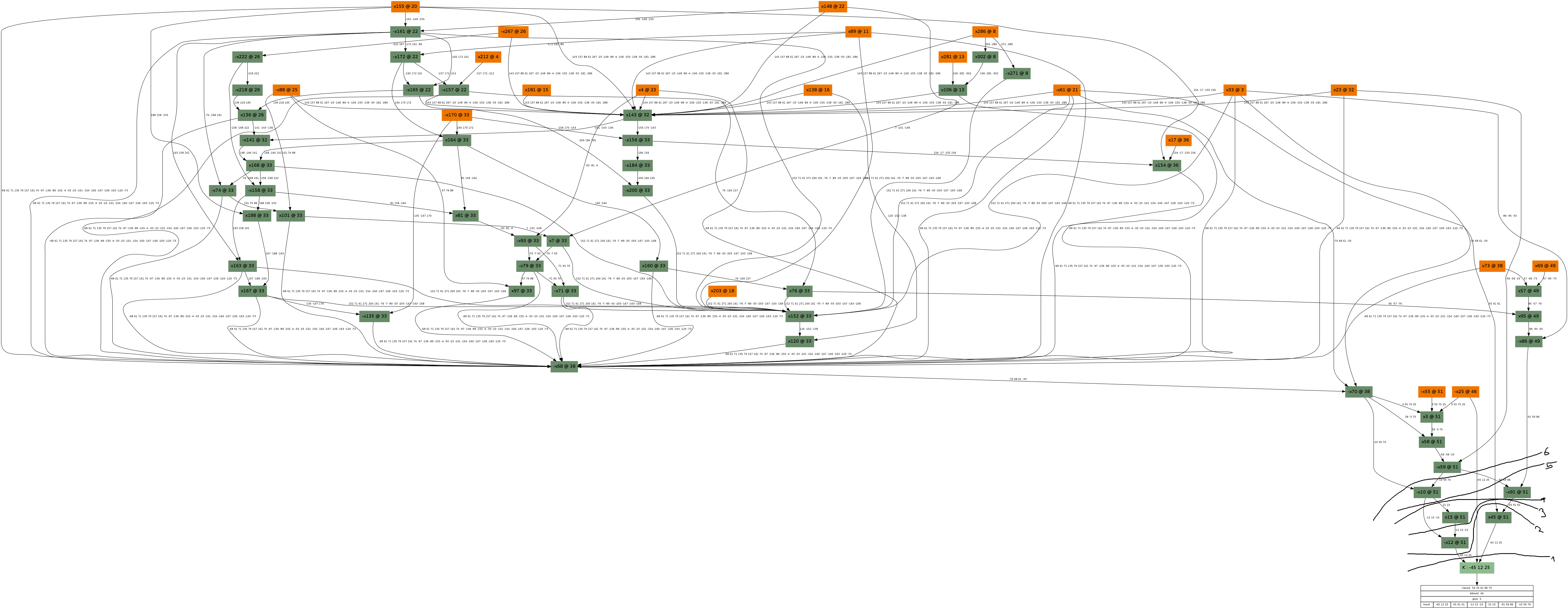
If you enjoyed the previous graph, here is another to entertain you further:

And its corresponding, not too obvious solution:
Note that I was too lazy to draw cuts 10, 11 and 12 around the assignment x145=FALSE (at decision level 39). The UIP in this case is again at the decision variable, x164. If you are still interested, here are some other examples:
PS: Thanks to George Katsirelos for his help understanding this (disclaimer: all faults belong to me alone).




{kind=link}
{kind=link}