The Internet is a pretty vast place. So I decided to curate a few links for you all for this special end-of-year period:
https://vimeo.com/41786246 A film about… a couch. That balances on a single leg. And sometimes falls, and falls apart, but with some care, and compassion, can be pieced back together.
https://www.newyorker.com/magazine/2016/08/29/michael-heizers-city About a land art piece by Michael Heizer, who is both a genius and is also rather crazy. His other work, Double Negative is truly beautiful (it’s literally a hole in the desert, but a beautiful hole, the best hole, and I mean it)
https://www.africavernaculararchitecture.com/ A classic 90s website about vernacular architecture in Africa. Some amazingly beautiful houses, built for the people, by the people, to live in. Click on a country and enjoy.
https://vimeo.com/58444378 A mockumentary about a guy making music, caring for his father, trying to enjoy life, and remembering the things that didn’t work out, which he likens to Mount Everest, his Whateverest.
https://www.vincentmoon.com/map/ The map of places where Vincent Moon recorded traditional music preformed by locals. Here is one for a taster. If you listen patiently, with intent, you might find that there’s a lot of beautiful music out there.
https://www.ryojiikeda.com/project/testpattern/ A set of test patterns, projected over a large space, that allows people to lay down, walk around, and explore. To be coupled with his strange but fascinating noise music. I went to his concert, it’s exactly as weird as you’d imagine. He never said hello, goodbye, or left any space to clap.
https://www.tate.org.uk/tate-etc/issue-10-summer-2007/excremental-value An article about my favourite artwork, Manzoni’s Merda d’Artista. In 1961 he put his own excrement into 90 small cans and sold them at the price of gold ($37/ounce). Over the years, it has outperformed gold by a factor of 70x. The guy with the banana stuck to the wall is a mere imitator by comparison (and 60 years late)
Ágnes Dénes – Wheatfield – A Confrontation, 1982, Battery Park Landfill, Downtown Manhattan, photo: John McGrall
I have recently had a few discussions with people who wanted to do some form of model counting, and I decided to put my thoughts about this problem into a single blog post, hopefully bringing some light to this area. Firstly, when talking about model counting, it’s very important to think through what one actually needs to achieve. When people talk about a model, they often mean a solution to a problem, described as a set of constraints over either purely boolean variables (so-called propositional model counting) expressed in so-called CNF, or over higher-level constraints, often expressed in SMT-LIB format.
Let’s look at a CNF example:
c this is a comment
c below line means there are 5 boolean variables and 2 constraints
p cnf 5 2
1 -2 0
1 -2 3 0
The above CNF has 5 boolean variables and 2 constraints: “v1 or (not v2) = true”, and “v1 or (not v2) or v3 = true”. In this case, if “v1 or (not v2) = true” is satisfied, the other constraint is also satisfied. So we effectively only have to satisfy the “v1 or -v2” constraint. There are 3 solutions over the variables v1 and v2 to this constraint: (1, 0), (1, 1), and (0,0). For variables v3, v4, and v5 we can choose anything. So there are a total of 3*2^3 = 24 solutions to this CNF.
Let’s look at an SMT problem:
(set-logic QF_BV) ; Set the logic to Quantifier-Free BitVectors
(declare-fun bv () (_ BitVec 8)) ; Declare an 8-bit value
(assert (not (= bv #x00))) ; Assert that 'bv' is not equal to zero
In this SMT-LIB problem, we declared that the logic we will be using is the so-called quantifier-free bitvector logic, which basically gives you access to fixed-width variables such as uint8_t, and of course all the logical and fixed-bit bitwector operators such as modulo addition, division, subtraction, etc. In this particular case, we declared an 8-bit variable and banned it from being 0, so this problem has 2^8-1 solutions, i.e. 255.
Whichever format is being used, “counting” of solutions is something that may sound trivial (it’s just a number!), but once we get a bit more fiddly, it turns out that we can do many things that are actually easier, or even harder, than just counting, even though they sound very close to, or are even synonymous with, counting :
Figuring out if there is at least one solution. This is more appropriately called satisfiability checking. This is significantly easier than any notion of counting listed below. However, even this can be challenging. Typically, in the SMT/SAT competition, this is the so-called SMT single query track or the SAT competition Main Track. All SAT and SMT solvers such as kissat or cvc5 can run this kind of task.
Next up in complexity is to figure out if there is exactly one solution. This is actually very close to satisfiability checking, and requires only two so-called “incremental calls” to the SMT/SAT solver. I have seen this question pop up a lot in zero-knowledge (ZK) circuit correctness. What is needed is to run the query as per the above, but then add a constraint that bans the solution that is output by the solver, and ask the system to be solved again. If the solver outputs UNSAT, i.e. unsatisfiable, then we know there are no more solutions, and we are happy with the result. If not, it gives us another solution, which is a witness that there are at least two solutions. These queries are answered by so-called incremental SMT solvers (SMT competition track here), or incremental SAT solvers (incremental SAT competition track here). Almost all SAT and SMT solvers can work incrementally, for example cvc5 or z3. Most SAT solvers work incrementally, too, but e.g. kissat does not, and you need to use CaDiCaL instead.
Next up in complexity is to approximately count the solutions. Here, we are not interested that there are exactly, say, 87231214 solutions, instead, we are happy to know that there are approx 2^26 solutions. This is often good enough, in case one wants to e.g. figure out probabilities. There are very few such systems available, for SMT there is csb, and for SAT there is ApproxMC. For the special case of approximate DNF counting, I’d recommend pepin.
Next up in the complexity is exactly counting the solutions. Here, we want to know how many solutions there are, exactly, and we really-really need the exact number. There are few solutions to doing this over SMT, but doing this over SAT is quite developed. For SMT, I would recommend following the csb approach, and running Ganak on the blasted SAT formula instead of ApproxMC, and for SAT, there is the annual model counting competition, where Ganak won every single category this year, so I’d recommend Ganak.
Next up is model enumeration where it’s not enough to count the solutions, but we need a way to compactly represent and store them all. This of course requires quite a bit of disk space, as there could be e.g. 2^100 solutions, and representing them all, even in a very compact format with lots of smart ideas can take a lot of space — but not necessarily exponential amount. Currently, there is no such system for SMT, and my understanding is that only the d4 model counter can do this on SAT/CNF problems, thanks to its proof checking system, in part thanks to Randal Byrant. Once Ganak can output a proof, it will also be able to do this.
All in all, there is a very large gap between “find if there is exactly one solution” and “enumerate all solutions” — even though I have seen these two notions being mixed up a few times. The first might take only a few seconds to solve, while the other might not even be feasible, because compactly representing all solutions may be too expensive in terms of space (and that’s not even discussing time).
One aspect to keep in mind is that often, one does not need all solutions. For example, if one only wants to find a good set of example solutions, then it is possible to use uniform-like samplers, that give a “somewhat uniform” set of example solutions from the solution space (without guarantees of uniformity). A good tool for this is cmsgen for CNF/SAT problems. If one needs a guaranteed uniform set of samples (to be exact, a probabilistically approximately uniform sample), then unigen is the way to go. Obviously, it’s quite easy to find a uniform sample once we have an enumeration of all solutions — simply pick a random one from the whole set — but that’s way more expensive than running unigen.
While all of the above is about counting, it’s often the case that one wants to optimize for something within the solution space. Basically, we have some kind of objective function that we want to optimize for (e.g. maximize profit, minimize loss) , and so we are looking for a solution that maximizes/minimizes some property. Of course, once we have done model enumeration, it’s quite easy to do this — simply run the objective function on all solutions, and pick the best! But that’s really hard. Instead, one can formulate the problem as a so-called MaxSAT or an SMT problem with an objective function. These systems run some really smart algorithms to significantly cut down search time, and even often keep a “best so far” solution around, so we can early-abort them and still get some kind of “best so far” solution.
All in all, it’s extremely important to figure out what one actually needs, because there are vast gaps in complexity between the problems (and corresponding algorithms) above. Even between something like approximate and exact counting, the gap is gigantic, as there are huge swaths of problems that are almost trivial to count approximately, but essentially impossible to exactly count with current technology:
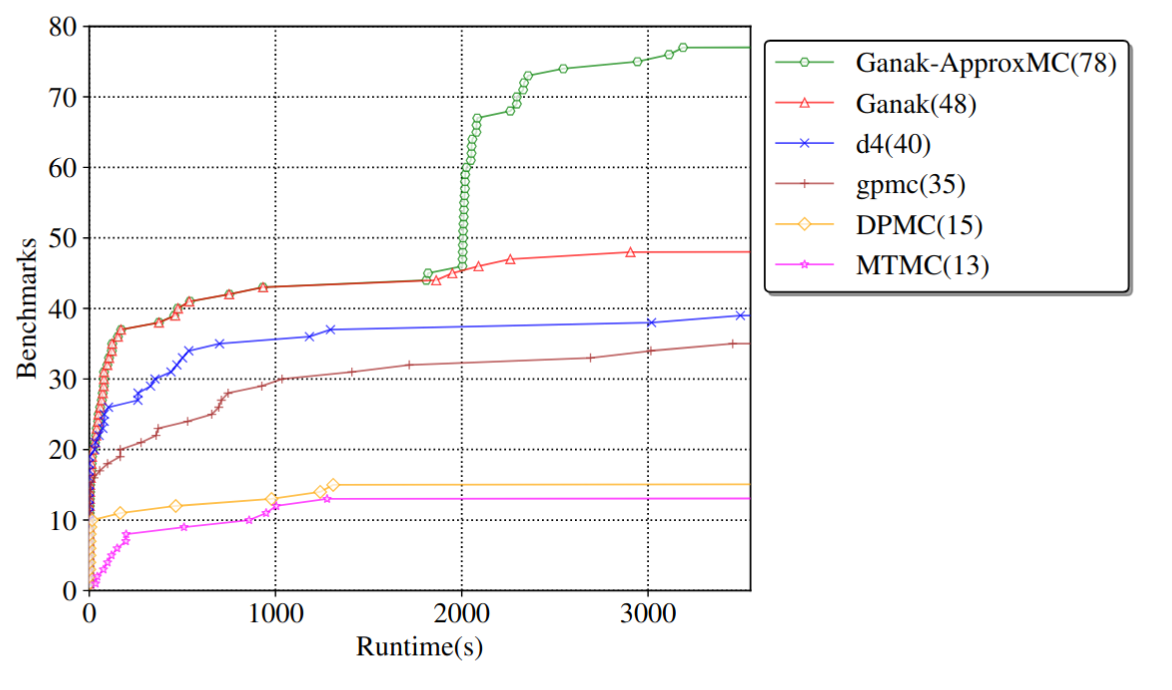
Here, the green line is a tool that changes its behaviour from exact to approximate model counting after 1800 seconds of solving, and the number of solved instances jumps significantly. Notice that the red line, the original system it runs for 1800s, is the best in class here, by a wide margin, and still the approximate counting that Ganak+ApprocMC switches into shows a massive difference.
This post is just a bit of a recap of what we have developed over the years as part of our toolset of SAT solvers, counters, and samplers. Many of these tools depend on each other, and have taken greatly from other tools, papers, and ideas. These dependencies are too long to list here, but the list is long, probably starting somewhere around the Greek period, and goes all the way to recent work such as SharpSAT-td or B+E. My personal work stretches back to the beginning of CryptoMiniSat in 2009, and the last addition to our list is Pepin.
Overview
Firstly when I say “we” I loosely refer to the work of my colleagues and myself, often but not always part of the research group lead by Prof Kuldeep Meel. Secondly, almost all these tools depend on CryptoMiniSat, a SAT solver that I have been writing since around 2009. This is because most of these tools use DIMACS CNF as the input format and/or make use of a SAT solver, and CryptoMiniSat is excellent at reading, transforming , and solving CNFs. Thirdly, many of these tools have python interface, some connected to PySAT. Finally, all these tools are maintained by me personally, and all have a static Linux executable as part of their release, but many have a MacOS binary, and some even a Windows binary. All of them build with open source toolchains using open source libraries, and all of them are either MIT licensed or GPL licensed. There are no stale issues in their respective GitHub repositories, and most of them are fuzzed.
CryptoMiniSat
CryptoMiniSat (research paper) our SAT solver that can solve and pre- and inprocess CNFs. It is currently approx 30k+ lines of code, with a large amount of codebase dedicated to CNF transformations, which are also called “inprocessing” steps. These transformations are accessible to the outside via an API that many of the other tools take advantage of. CryptoMiniSat used to be a state-of-the-art SAT solver, and while it’s not too shabby even now, it hasn’t had the chance to shine at a SAT competition since 2020, when it came 3rd place. It’s hard to keep SAT solver competitive, there are many aspects to such an endeavor, but mostly it’s energy and time, some of which I have lately redirected into other projects, see below. Nevertheless, it’s a cornerstone of many of our tools, and e.g. large portions of ApproxMC and Arjun are in fact implemented in CryptoMiniSat, so that improvement in one tool can benefit all other tools.
Arjun
Arjun (research paper) is our tool to make CNFs easier to count with ApproxMC, our approximate counter. Arjun takes a CNF with or without a projection set, and computes a small projection set for it. What this means is that if say the question was: “How many solutions does this CNF has if we only count solutions to be distinct over variables v4, v5, and v6?”, Arjun can compute that in fact it’s sufficient to e.g. compute the solutions over variables v4 and v5, and that will be the same as the solutions over v4, v5, and v6. This can make a huge difference for large CNFs where e.g. the original projection set can be 100k variables, but Arjun can compute a projection set sometimes as small as a few hundred. Hence, Arjun is used as a preprocessor for our model counters ApproxMC and GANAK.
ApproxMC
ApproxMC (research paper) is our probabilistically approximate model counter for CNFs. This means that when e.g. ApproxMC gives a result, it gives it in a form of “The model count is between 0.9*M and 1.1*M, with a probability of 99%, and with a probability of 1%, it can be any value”. Which is very often enough for most cases of counting, and is much easier to compute than an exact count. It counts by basically halfing the solution space K times and then counts the remaining number of solutions. Then, the count is estimated to be 2^(how many times we halved)*(how many solutions remained). This halfing is done using XOR constraints, which CryptoMiniSat is very efficient at. In fact, no other state-of-the-art SAT solver can currently perform XOR reasoning other than CryptoMiniSat.
UniGen
UniGen (research paper) is an approximate probabilistic uniform sample generator for CNFs. Basically, it generates samples that are probabilistically approximately uniform. This can be hepful for example if you want to generate test cases for a problem, and you need the samples to be almost uniform. It uses ApproxMC to first count and then the same idea as ApproxMC to sample: add as many XORs as needed to half the solution space, and then take K random elements from the remaining (small) set of solutions. These will be the samples returned. Notice that UniGen depends on ApproxMC for counting, Arjun for projection minimization, and CryptoMiniSat for the heavy-lifting of solution/UNSAT finding.
GANAK
GANAK (research paper, binary) is our probabilistic exact model counter. In other words, it returns a solution such as “This CNF has 847365 solutions, with a probability of 99.99%, and with 0.01% probability, any other value”. GANAK is based on SharpSAT and some parts of SharpSAT-td and GPMC. In its currently released form, it is in its infancy, and while usable, it needs e.g. Arjun to be ran on the CNF before, and while competitive, its ease-of-use could be improved. Vast improvements are in the works, though, and hopefully things will be better for the next Model Counting Competition.
CMSGen
CMSGen (research paper) is our fast, weighted, uniform-like sampler, which means it tries to give uniform samples the best it can, but it provides no guarantees for its correctness. While it provides no guarantees, it is surprisingly good at generating uniform samples. While these samples cannot be trusted in scenarios where the samples must be uniform, they are very effective in scenarios where a less-than-uniform sample will only degrade the performance of a system. For example, they are great at refining machine learning models, where the samples are taken uniformly at random from the area of input where the ML model performs poorly, to further train (i.e. refine) the model on inputs where it is performing poorly. Here, if the sample is not uniform, it will only slow down the learning, but not make it incorrect. However, generating provably uniform samples in such scenarios may be prohibitively expensive. CMSGen is derived from CryptoMiniSat, but does not import it as a library.
Bosphorus
Bosphorus (research paper) is our ANF solver, where ANF stands for Algebraic Normal Form. It’s a format used widely in cryptography to describe constraints over a finite field via multivariate polynomials over a the field of GF(2). Essentially, it’s equations such as “a XOR b XOR (b AND c) XOR true = false” where a,b,c are booleans. These allow some problems to be expressed in a very compact way and solving them can often be tantamount to breaking a cryptographic primitive such as a symmetric cipher. Bosphorus takes such a set of polynomials as input and either tries to simplify them via a set of inprocessing steps and SAT solving, and/or tries to solve them via translation to a SAT problem. It can output an equivalent CNF, too, that can e.g. be counted via GANAK, which will give the count of solutions to the original ANF. In this sense, Bosphorus is a bridge from ANF into our set of CNF tools above, allowing cryptographers to make use of the wide array of tools we have developed for solving, counting, and sampling CNFs.
Pepin
Pepin (research paper) is our probabilistically approximate DNF counter. DNF is basically the reverse of CNF — it’s trivial to ascertain if there is a solution, but it’s very hard to know if all solutions are present. However, it is actually extremely fast to probabilistically approximate how many solutions a DNF has. Pepin does exactly that. It’s one of the very few tools we have that doesn’t depend on CryptoMiniSat, as it deals with DNFs, and not CNFs. It basically blows all other such approximate counters out of the water, and of course its speed is basically incomparable to that of exact counters. If you need to count a DNF formula, and you don’t need an exact result, Pepin is a great tool of choice.
Conclusions
My personal philosophy has been that if a tool is not easily accessible (e.g. having to email the authors) and has no support, it essentially doesn’t exist. Hence, I try my best to keep the tools I feel responsible for accessible and well-supported. In fact, this runs so deep, that e.g. CryptoMiniSat uses the symmetry breaking tool BreakID, and so I made that tool into a robust library, which is now being packaged by Fedora, because it’s needed by CryptoMiniSat. In other words, I am pulling other people’s tools into the “maintained and supported” list of projects that I work with, because I want to make use of them (e.g. BreakID now builds on Linux, MacOS, and Windows). I did the same with e.g. the Louvain Community library, which had a few oddities/issues I wanted to fix.
Another oddity of mine is that I try my best to make our tools make sense to the user, work as intended, give meaningful (error) messages, and good help pages. For example, none of the tools I develop call subprocesses that make it hard to stop a computation, and none use a random number seed that can lead to reproducibility issues. While I am aware that working tools are sometimes less respected than a highly cited research paper, and so in some sense I am investing my time in a slightly suboptimal way, I still feel obliged to make sure the tax money spent on my academic salary gives something tangible back to the people who pay for it.
Many modern SAT solvers do a lot of what’s called inprocessing. These steps simplify the CNF into something that is easier to solve. In the compiler world, these are called rewritngs since the effectively rewrite (parts of) the formula to something else that retain certain properties, such as satisfiability. One of the most successful such rewrite rules for CNF is Bounded Variable Elimination (BVE, classic paper here), but there are many others. These rewrites are usually done by modern SAT solvers in a particular order that was found to be working well for their particular use-case, but they are not normally accessible from the outside.
Sometimes one wants to use these rewrite rules for something other than just solving the instance via the SAT solver. One such use-case is to use these rewrite rules to simplify the CNF in order to count the solution to it. In this scenario, the user wants to rewrite the CNF in a very particular way, and then extract the simplified CNF. Other use-cases are easy to imagine, such as e.g. MaxSAT, core counting, etc. Over the years, CryptoMiniSat has evolved such a rewrite capability. It is possible to tell CryptoMiniSat to simplify the formula exactly how the user wants the solver to be satisfied and then extract the simplified formula.
Example Use-Case
Let’s say we have a CNF that we want to simplify:
p cnf 4 2
1 2 3 4 0
1 2 3 0
In this CNF, 1 2 3 4 0 is not needed, because it is subsumed by the clause 1 2 3 0. You can run subsumption using CryptoMiniSat this way:
This code runs the inprocessing system occ-backw-sub, which stands for backwards subsumption using occurrence lists. The input CNF can be anything, and the output CNF is the simplified CNF. This sounds like quite a lot of code for simple subsumption, but this does a lot of things under the hood for things to be fast, and it is a lot more capable than just doing subsumption.
Notice that the first argument we passed to simplify() is NULL. This means we don’t care about any variables being preserved — any variable can (and will) be eliminated if occ-bve is called. In case some variables are important to you not to be eliminated, you can create a vector of them and pass the pointer here. If you have called the renumber API, then you can get the set of variables you had via clean_sampl_and_get_empties(). The numbering will not be preserved, but their set will be the same, though not necessarily the same size. This is because some variables may have been set, or some variables may be equivalent to other variables in the same set. You can get the variables that have been set via get_zero_assigned_lits().
Supported Inprocessing Steps
Currently, the following set of inprocessing steps are supported:
API name
Inprocessing performed
occ-backw-sub
Backwards subsumption using occurence lists
occ-backw-sub-str
Backwards subsumption and strengthening using occurence lists
Distill long clauses, but only remove clauses, don’t shorten them. Useful if you want to make sure BVE can run at full blast after this step.
clean-cls
Clean clauses of set literals, and delete satisfied clauses
must-renumber
Renumber variables to start from 0, in case some have been set to TRUE/FALSE or removed due to equivalent literal replacement.
must-scc-vrepl
Perform strongly connected component analysis and perform equivalent literal replacement.
oracle-vivify
Vivify clauses using the Oracle tool by Korhonen and Jarvisalo (paper). Slow but very effective.
oracle-vivif-sparsify
Vivify & sparsify clauses using the Oracle tool by Korhonen and Jarvisalo. Slow but very effective.
Convenience Features Under the Hood
The steps above do more than what they say on the label. For example, the ones that start with occ build an occurrence list and use it for the next simplification stop if it also starts with occ. They also all make sure that memory limits and time limits are adhered to. The timeout multiplier can be changed via set_timeout_all_calls(double multiplier). The time limits are entirely reproducible, there is no actual seconds, it’s all about an abstract “tick” that is ticking. This means that all bugs in your code are always reproducible. This helps immensely with debugging — no more frustrating Heisenbugs. You can check the cryptominisat.h file for all the different individual timeouts and memouts you can set.
Under the hood you also get a lot of tricks implemented by default. You don’t have to worry about e.g. strengthening running out of control, it will terminate in reasonable amount of ticks, even if that means it will not run to completion. And the next time you run it, it will start at a different point. This makes a big difference in case you actually want your tool to be usable, rather than just “publish and forget”. In many cases, simplification only makes things somewhat faster, and you want to stop performing the simplification after some time, but you also want your users to be able to report bugs and anomalies. If the system didn’t have timeouts, you’d run the risk of the simplifier running way too long, even though the actual solving would have taken very little time. And if the timeout was measured in seconds, you’d run the risk of a bug being reported but being irreproducible, because the exact moment the timeout hit for the bug to occur would be irreproducible.
Making the Best of it All
This system is just an API — it doesn’t do much on its own. You need to play with it, and creatively compose simplifications. If you take a look at cryptominisat.h, it already has a cool trick, where it moves the simplified CNF from an existing solver to a new, clean solver through the API, called copy_simp_solver_to_solver(). It is also used extensively in Arjun, our CNF simplifier for counting. There, you can find the function that controls CryptoMiniSat from the outside to simplify the CNF in the exact way needed. It may be worthwhile reading through that function if you want to control CryptoMiniSat via this API.
The simplify() API can give you the redundant clauses, too (useful if you e.g. did ternary or hyper-binary resolution), and can give you the non-renumbered CNF as well — check out the full API in cryptominisat.h, or the Arjun code. Basically, there is a red and a simplified parameter you can pass to this function.
Perhaps I’ll expose some of this API via the Python interface, if there is some interest for it. I think it’s quite powerful and could help people who use CNFs in other scenarios, such as MaxSAT solving, core counting, core minimization, etc.
Closing Thoughts
I think there is currently a lack of tooling to perform the already well-known and well-documented pre- and inprocessing steps that many SAT solvers implement internally, but don’t expose externally. This API is supposed to fill that gap. Although it’s a bit rough on the edges sometimes, hopefully it’s something that will inspire others to either use this API to build cool stuff, or to improve the API so others can build even cooler stuff. While it may sound trivial to re-implement e.g. BVE, once you start going into the weeds of it (e.g. dealing with the special case of detecting ITE, OR & AND gates’ and their lower resolvent counts, or doing it incrementally with some leeway to allow clause number increase), it gets pretty complicated. This API is meant to alleviate this stress, so researchers and enthusiasts can build their own simplifier given a set of working and tested “LEGO bricks”.
Let’s say you are allowed to have cubes in a 3-dimensional space that happens to be binary. In this space, x1, x2, and x3 are the axis, and for example the cube x1=0 is a cube that happens to have 4 points in it: 000, 001, 010, and 011. So far, so good. Now, let’s say we need to calculate the total volume of two cubes in this space. If they don’t intersect, it’s quite easy, we simply add their volumes. But what if they intersect? Now we need to compute their overlap, and subtract it from their sum of volumes. But there is a better way.
Probabilistic Approximate Volume Counting
Our new tool Pepin (code, paper) is based on the probabilistic approximate model counting algorithm by Meel, Vinodchandran, and Chakraborty (paper) that is so simple in principle yet so ingenious that even Donald Knuth got excited about it, recently writing a 15-page note and spending considerable amount of time on the algorithm.
So, what is this algorithm? Well, it’s so simple it’s almost funny. Basically, we keep randomly sampled points from the volume that we currently hold. At every moment we have a representative, evenly sampled set of points from the volume we currently have, and we know the sampling rate. You can think of the “sampling rate” as the approximate volume that each sample represents. So, if at any point we want to know the volume, we calculate number_of_points*(1/sampling_rate) and have the approximate volume. Kinda neat, no? So all we need is a randomly sampled set of points and a corresponding sampling rate. But how do we go about that?
Let’s say we are about to process the first cube (i.e. volume, could be any shape, actually, but cubes are simple). Our sampling rate is 1.0, we have 10 dimensions, and we have a limit of 10 samples in our bag. Let’s say the first cube is:
x1=0
Notice that this cube has 2^9 elements: 0000000000, 0000000001, … 0111111111. But that’s too many elements to hold, we only have space for 10 samples in the bag! We have to drop our sampling rate. The algorithm throws coins for each element in the volume (at first, a coin that has 1.0 probability of heads… funny coin!), and realizes that it won’t fit the sample bag. So it halves the sample rate (to 0.5) and throws the coins again. Realizes it doesn’t fit… halves the sample rate… and eventually will likely end up with a sampling rate of 1/2^6. That sample rate makes sense: it means 2^9/2^6 = 9 samples on average, which fits. Let’s say the algorithm flipped the coins, halved the sampling rate every time, and settled on a sampling rate of 1/2^6, and 9 samples.
Let’s see these samples. For readability, I’ll write the samples as 0110… which means x1=0, x2=1, x3=1, x4=0, etc.
Think of each of these points representing a volume of 2^6. The current estimate of the volume is 9*2^6 = 2^9.17 (instead of 2^9). So far so good. Now a new cube comes in. Let’s say this cube is:
x1=0, x1=1
This is the tricky part. What do we do? The algorithm is extremely simple: we throw away every sample that matches this cube, and then we sample the cube. Let’s throw away everything that matches, i.e. everything that starts with “01”:
Good. Now we sample the cube “x1=0, x1=1” with 1/2^6 probability. Time to take out our weird coin that has a 1/2^6 chance of winning! We toss this coin on every element in the cube, i.e. all 2^8 (since x0=1, x1=1 has 2^8 elements). We should get about 4 heads, but let’s say we got 3. Happens. Now, append these 3 to our neat little sample bag:
Nice. What just happened? Well, we got rid of the elements from the volume we were holding that were contained in the cube that we are processing. Then, we randomly sampled elements from the cube at our given sampling rate. If you think about it, this means that as long as we did everything uniformly at random, we are basically back to where we started. In fact, the 2nd cube could have been anything. It could have been completely outside of our current volume, or it could have partially intersected it. The game is the same. Running out of space? Just throw away each sample with probability half, and half your sampling rate! Here’s a visual representation what we would do in case the two cubes partially intersected:
As the number of samples goes over the limit in our bag, we simply throw away each sample with 0.5 probability, and halve our sampling rate. This allows us to keep a fixed maximum number of samples, regardless of the size of the volume we are holding. For our example, we decided to limit ourselves to 10 samples, and got a pretty good estimate of the volume: 9*2^6 (=~2^9.17) instead of 2^9. One thing of note. This algorithm is not only approximate in the sense that we get something close to the actual solution, like 2^9.17. It’s also probabilistic in the sense that with a low probability, we get a complete garbage value. You can reduce the probability of getting a garbage value in a number of ways, though.
This algorithm is really powerful, because you could approximately count a 100-dimensional volume with thousands of cubes using less than 1MB of memory, and actually be pretty damn accurate, with a very low probability of getting a wrong value. Unsurprisingly, this is exactly what we do in our tool, Pepin.
The Tricks of Pepin
If you think about it, Pepin does nothing but: (1) holds a bunch of samples (2) deals with some large & small numbers (2^10000 is large, and 1/2^100000 is small), and (3) deals with probabilities. For dealing with small & large numbers, we used the GNU MP Bignum library, with all the standard tricks (pre-allocating memory & constants, etc), and for probabilities we use a number of tricks — sampling the binomial distribution is easy until you have to do it with t=2^100 and p=1/2^95. While dealing with probabilities was hard from a mathematical perspective, the really fun part for me was dealing with the sampling bag.
It turns out I wasn’t the only one who got sidetracked with the sampling bag: if you take a look at Knuth’s implementation, he goes into great detail about his datastructure, the Treap (honestly, that whole note by Knuth is quite a trip, you can see how his mind is racing). Anyway, back to the sampling bag. Firstly, the bag is just a matrix (with some rows sometimes empty) so we can store it either column or row-major. This is probably the first thing that comes to everyone’s mind as a computer science 101 trick. More interestingly, if one looks at the performance bottlenecks of the algorithm, it quickly becomes apparent that: (1) generating millions of bits of randomness for all the samples is expensive, and (2) writing all those samples to memory is expensive. So, what can we do?
The cool trick we came up with is what Knuth would call “late binding”, or we can call it lazy evaluation. Let’s keep to our original example: we first had the cube “x1=1”. We ran our coin-flip technique and found that we needed 9 samples (setting the sampling rate to 1/2^6), fine. But why do we really need all the bits of the samples? We don’t need them now! We may need them later — but since it’s all random anyway, we can generate them anytime, now or later! So, let’s generate 9 samples like this:
The “*” simply means this bit needs to be selected randomly. Now the cube “x1=1, x2=0” comes, which forces our hands, we have to know what the 2nd bit is: if it’s a “1” we have to throw the sample away, if it’s a “0”, we can keep it in. So we decide this bit now (not in the past, but now, when we need it), randomly:
We can now sample from the cube “x1=0, x2=1” randomly — again, notice we don’t need to know what the 3rd or 4th, etc. bits are. They can be decided later, when they are needed:
Nice. Notice that this leads to exactly where we would have arrived anyway from a conceptual point of view. Except we (1) don’t need to generate as many random numbers and (2) if we can fill memory with “*” faster, then we can sample much faster.
In our implementation, we store values mem-packed, with 2 bits representing 0/1/*: for us, 00=0, 01=1, 11=*. This way, we can simply memset() with 1-s and fill it all up with “*”, a common occurrence. It probably won’t surprise anyone that of course we tried using a sparse matrix representation as well. It works very well for some problems. However, it depends what the exact problem is, and the performance degrades drastically for many problems. So the system uses dense representation by default. I’d be happy to merge a pull request that flips between sparse and dense depending on some density metric.
Obviously, I could not have done any of this alone. Pepin, the tool & paper, is by Divesh Aggarwal, Sourav Chakraborty, Kuldeep S. Meel, Maciej Obremski, and myself. Honestly speaking, it was wonderful to work together with all these amazing people.
Performance
At this stage, it should be obvious that it doesn’t even make sense to compare this tool to exact methods. The difference is mind-boggling. It’d be like racing a fighter jet against a rabbit. It’s a lot more fun to compare against other, existing approximate volume counting tools.
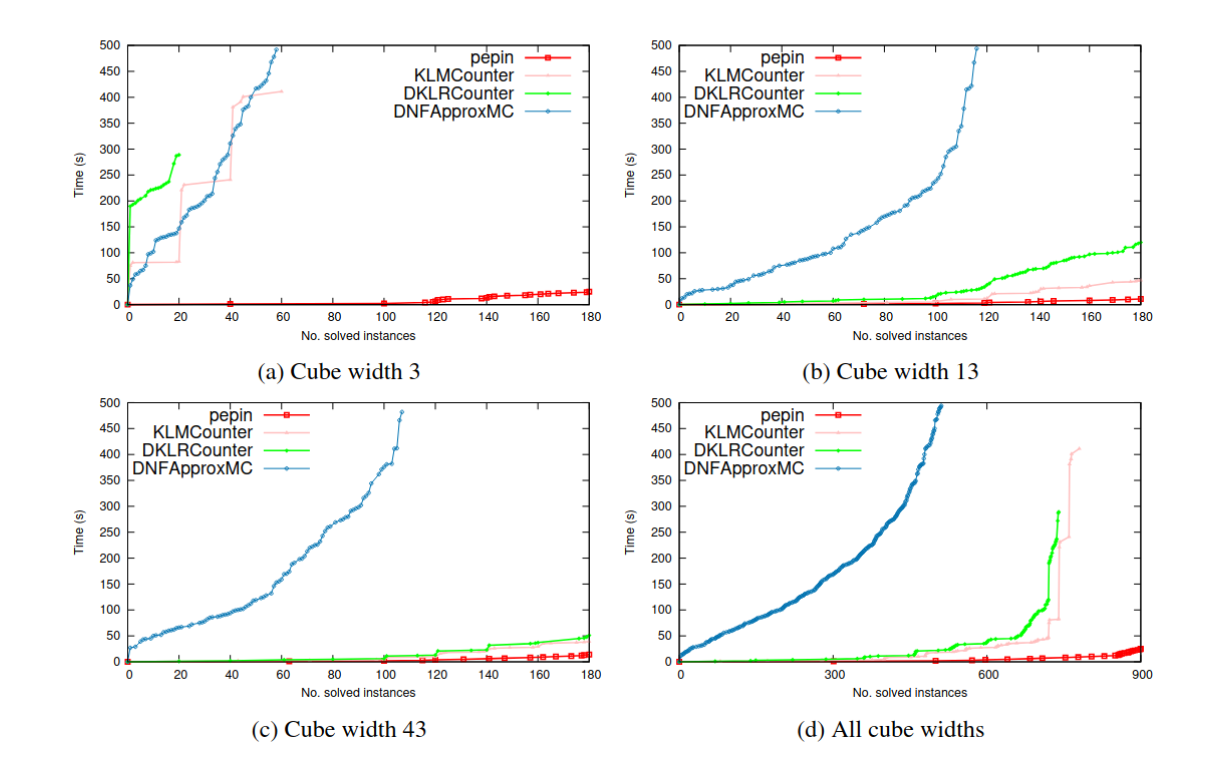
Above is a set of graphs of how Pepin performs against other approximate volume counting tools. Basically, it’s either way faster (easy 1000x speedup), or it’s a lot faster. Graph (c) is a bit misleading: for completeness, we included DNFApproxMC (PDF), which performs very poorly on these problems, and so Pepin seems to perform “as well as the others”. But, on closer examination, it’s about 3x faster than any other.
Potential Future Work
As mentioned above, a pretty straightforward (but not trivial) improvement would be to automatically switch to a sparse matrix representation. This would be akin to “making the horse run faster”, rather than inventing the steam engine, but hey, if it works, it works. Building a steam engine would be more like putting the whole algorithm into GPGPU and/or parallelizing it. It should be possible to rewrite this algorithm in a dynamic programming way, as it should be possible to combine sample bags and sampling probabilities (maybe not, I’m just an engineer). Then you can do divide-and-conquer. If you do that over a GPGPU that has 1000+ streaming cores, it could be possible to make this whole thing run 100x+ faster.
As engineers we like to over-engineer for performance, so it’s important to keep in mind that we are already hundreds of times faster than exact algorithms. Hence, perhaps it’d be more interesting to come up with interesting use-cases, rather than focusing on further improving speed. To keep with the horse analogy, it may be useful not to put the cart in front of the horse.
Closing Thoughts
Approximate volume counting is actually really cool. It takes the power of randomization and uses it to its own advantage to make something really difficult into something that one could explain a child. I have a feeling we could make a few beautiful graphics and teach this algorithm to 12 year olds. The sample-in-a-bag idea is so simple, yet so powerful. Actually, it’s also incredibly weird if you start going into the weeds of it. Like, what happens when the size of your bag is 1? It’s the kind of question that only Knuth would ask, and then answer with clarity and prowess that only one with deep mathematical insight can. I won’t even entertain the thought, but you can, if you read his notes and then work on his questions.
PS: Pepin was named after the rather eccentric character of the same name from Bohumil Hrabal‘s book Cutting It Short, also released as a film. Pepin in the book was inspired by Hrabal’s own uncle who came to visit his hometown for two weeks but stayed for 40 years. I think we have all been there.